AI Agent Memory Patterns
- Entity Graph recall: Entity Graph achieved 100% recall (10/10) in this captured Cazton run by storing structured entity documents with vector embeddings in Azure Cosmos DB for NoSQL, while Sliding Window reached only 60% recall at one-third fewer prompt tokens.
- Four strategies benchmarked: Direct LLM, Sliding Window, Hierarchical 3-tier, and Entity Graph were measured on recall rate, average prompt tokens, and latency using a 60-message Cazton seed dataset.
- Summary compression risk: Summary-based strategies lose specific identifiers such as URLs and numeric values under compression; Entity Graph preserves them as queryable structured documents that survive any conversation length.
- Memory reduces latency: Memory-backed strategies responded faster than Direct LLM in this run because structured context produces concise, confident answers instead of lengthy elaborations on missing information.
- Zero-migration upgrade path: All four strategies share the same Azure Cosmos DB partition key and OpenAI integration model, so upgrading from Sliding Window to Entity Graph is an application-layer change with no infrastructure migration required.
- Advanced Cosmos DB capabilities: Azure Cosmos DB for NoSQL offers DiskANN vector indexes, float16 storage, filtered vector search, Hybrid RRF, and hierarchical partition keys, each of which materially improves retrieval quality or reduces cost at scale.
- Implementation companion: For the complete Python and .NET code behind every strategy in this benchmark, see the companion article Code Walkthrough: AI Agent Memory Patterns.
- Top clients: We help Fortune 500, large, mid-size, and startup companies with AI development, consulting, and hands-on training services. Our clients include Microsoft, Google, Broadcom, Thomson Reuters, Bank of America, Macquarie, Dell, and more.
Executive Summary
A practical comparison of four state-management patterns for multi-turn AI workflows, ranging from zero memory to structured entity graphs, using one captured run on a Cazton seed dataset.
- 100% - Entity Graph Recall (10/10 questions)
- 60% - Sliding Window Recall (6/10 questions)
- 1,100 - Lowest Average Prompt Tokens (memory-enabled strategy)
In this captured run, summary-based strategies dropped some specific identifiers (URLs, names, numbers) in longer conversations. Treat this as directional evidence, not a universal rule.
- Highest recall in this run: Entity Graph - 10/10 passes in the Cazton run log shown below.
- Lowest average prompt cost (memory-enabled): Sliding Window - about 33% fewer prompt tokens than Entity Graph in this run, with 6/10 passes.
- Recommendation: Start with Sliding Window for short conversations (under 30 turns). Switch to Entity Graph when high identifier-level recall matters; in this implementation, the upgrade is an application-layer change, not an infrastructure migration.
Introduction
Large Language Models are stateless by design. Every API call starts with a blank slate. Without persistent memory, your AI assistant forgets everything the moment a conversation exceeds its context window, or even between turns.
This article presents a scoped comparison of four memory architectures for multi-turn AI agents, using Azure Cosmos DB for NoSQL and OpenAI gpt-5.4. We use a Cazton seed dataset (60 factual messages) plus a single captured run log. Results show how each strategy behaved in this environment; validate against your own workload before standardizing. For the complete Python and .NET implementation of every strategy covered here, see the companion article Code Walkthrough: AI Agent Memory Patterns.
The Core Question
If you get the same correct answer from three different memory strategies, does it matter which one you use? Absolutely. The difference lies in token cost, latency, scalability, and what actually happens as conversations grow beyond 30, 50, or 100 turns.
- 4 Memory Strategies Compared
- 60 Cazton Seed Messages
- 10 Recall Questions Tested
- 100% Entity Graph Recall Rate (this run)
The Four Strategies
Each strategy represents a different philosophy for managing conversational state. They range from "no memory at all" to "structured knowledge graph with vector retrieval."
Strategy 0 - Direct LLM (No Memory)
The baseline. Each turn sends only the system prompt and the current user message. Zero history, zero recall.
- Stored in Cosmos: Session metadata only (turn count, timestamp)
- Context sent: System prompt + 1 message
- Prompt tokens: ~90 per turn
- Recall ability: None
Strategy 1 - Sliding Window
Keeps the last 30 messages verbatim plus a rolling summary of older messages. Extracts identity and numeric anchors via regex.
- Window: 30 messages + rolling summary
- TTL: 1 hour
- Summarizer:
gpt-5.4 - Weakness: Summary drift loses specific details (URLs, exact names)
Strategy 2 - Hierarchical (3-Tier)
Three memory tiers: 10 recent messages (hot), up to 4 summary blocks (warm), and a persistent facts document (cold).
- Tier 1: Last 10 verbatim messages
- Tier 2: Summary blocks (every 10 messages, max 4)
- Tier 3: Extracted bullet-point facts (persistent)
- Weakness: Still summarizes, which can lose some precision
Strategy 3 - Entity Graph
Stores structured entity documents with facts, relationships, and vector embeddings. Retrieves relevant entities per query using Cosmos DB vector search.
- Recent: Last 3 turn pairs (6 messages)
- Entities: Normalized docs with facts + embeddings
- Retrieval: Vector + lexical fallback (full-text search and Hybrid RRF were not enabled in this run)
- Strength: High precision for specific facts, URLs, and relationships in this run
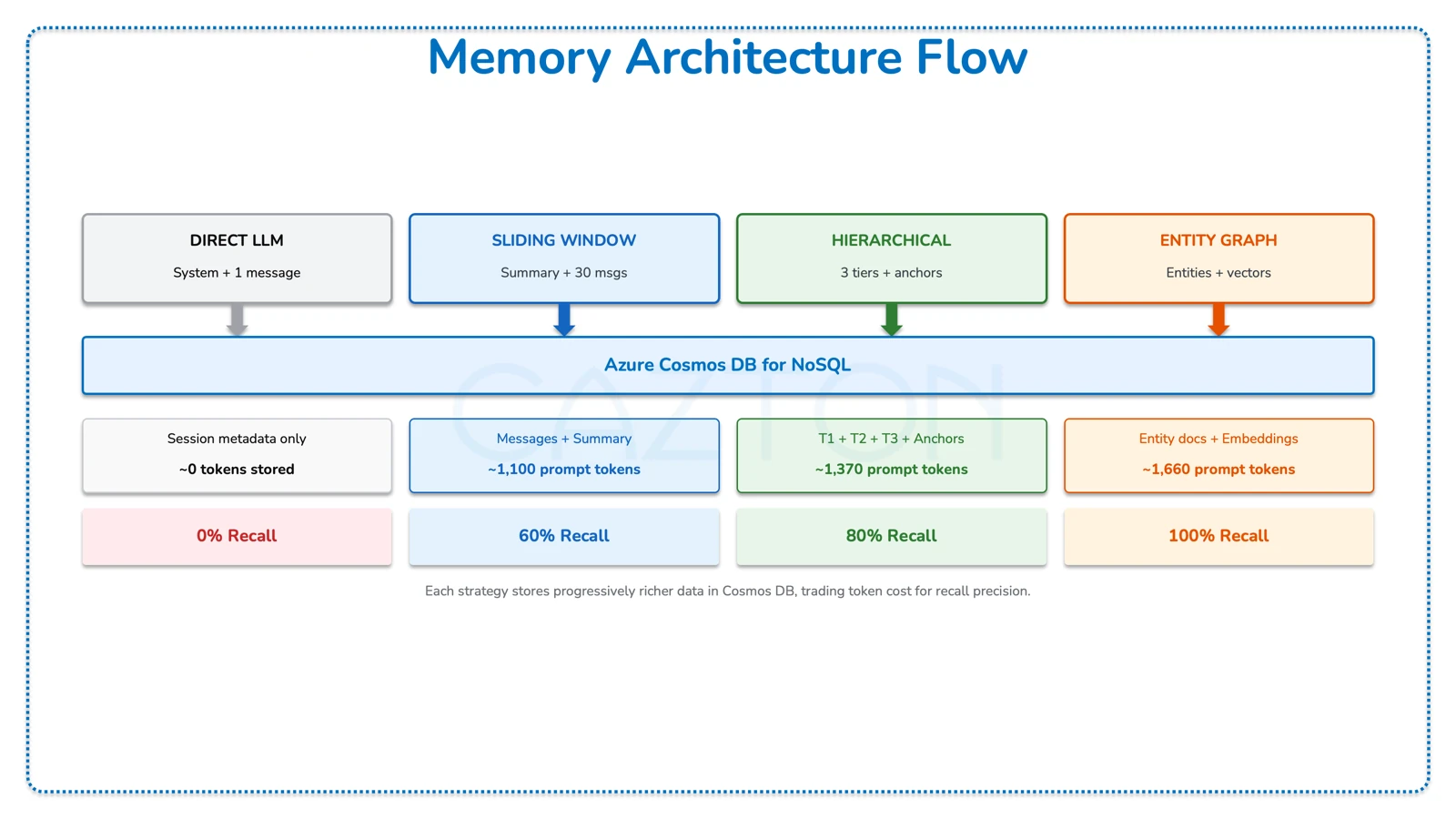
How They Work - Architecture Comparison
The following table summarizes how each strategy stores data in Azure Cosmos DB for NoSQL and what it sends to the LLM as context:
| Strategy | Context Sent to LLM | Storage in Cosmos | Avg Prompt Tokens | Recall (This Run) |
|---|---|---|---|---|
| Direct LLM | System prompt + 1 message | Session metadata only | ~90 | 0% |
| Sliding Window | Summary + last 30 messages | Messages + rolling summary | ~1,100 | 60% |
| Hierarchical | 3 tiers + anchors | Tier 1 messages + Tier 2 summaries + Tier 3 facts | ~1,370 | 80% |
| Entity Graph | User identity + entity bullets + last 6 messages | Entity docs + embeddings | ~1,660 | 100% |
Each strategy stores progressively richer data in Cosmos DB, trading token cost for recall precision.
Same Result, Different Cost
In the first five core recall questions of this run, all three memory strategies (Sliding Window, Hierarchical, Entity Graph) returned the expected answer. Cost still varied materially.
Example 1 - What Are the Three Headline Offerings?
After ingesting 60 Cazton fact messages, we ask a basic recall question. All three memory strategies returned the expected answer, with different token and latency profiles:
| Strategy | Status | Prompt Tokens | Total Tokens | Latency | Answer |
|---|---|---|---|---|---|
| Direct LLM | BASELINE | 93 | 149 | 1,743 ms | "I don't have access..." |
| Sliding Window | PASS | 1,335 | 1,360 | 826 ms | Consulting, Training, Recruiting |
| Hierarchical | PASS | 1,307 | 1,351 | 1,012 ms | Consulting, Training, Recruiting |
| Entity Graph | PASS | 1,773 | 1,817 | 1,058 ms | Consulting, Training, Recruiting |
Key Insight: For this question, Sliding Window used 25% fewer prompt tokens than Entity Graph and returned 22% faster. When the answer is in recent context, simpler context assembly can be cheaper.
All Five Core Rounds - Cazton Dataset
Here is the complete picture across all five core recall questions:
| Question | Direct LLM | Sliding Window | Hierarchical | Entity Graph |
|---|---|---|---|---|
| Three headline offerings? | BASELINE | PASS | PASS | PASS |
| Leadership profile URL? | BASELINE | PASS | PASS | PASS |
| Cosmos video & ebook slugs? | BASELINE | PASS | PASS | PASS |
| Contact & workshops paths? | BASELINE | PASS | PASS | PASS |
| Canonical URL & OG image? | BASELINE | PASS | PASS | PASS |
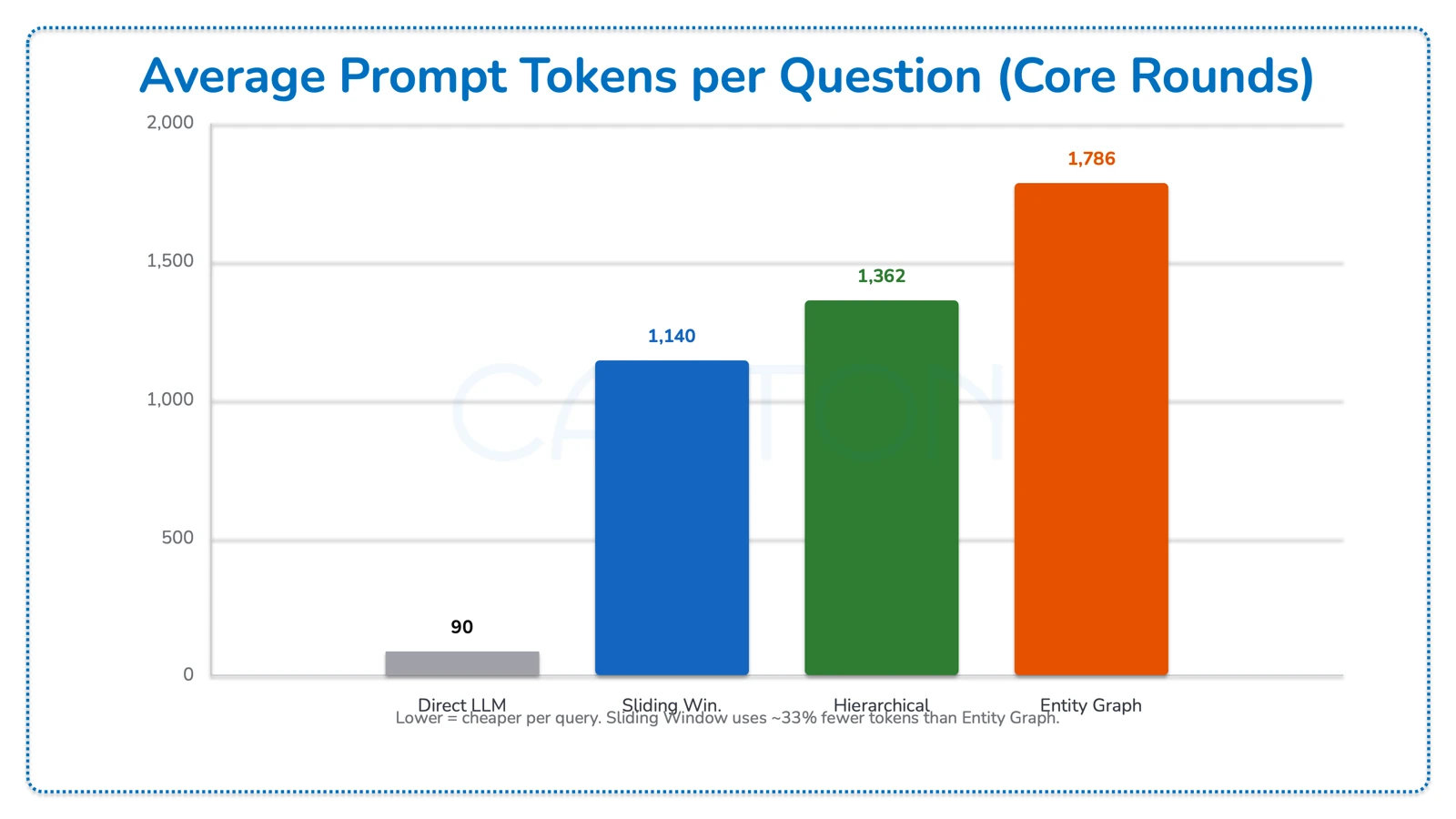
Average Prompt Tokens per Question (Core Rounds)
| Strategy | Avg Prompt Tokens (Core Rounds) |
|---|---|
| Direct LLM | 90 |
| Sliding Window | 1,140 |
| Hierarchical | 1,362 |
| Entity Graph | 1,786 |
Average Latency per Question (Core Rounds)
| Strategy | Avg Latency (ms) |
|---|---|
| Direct LLM | 1,718 |
| Sliding Window | 1,068 |
| Hierarchical | 1,243 |
| Entity Graph | 1,116 |
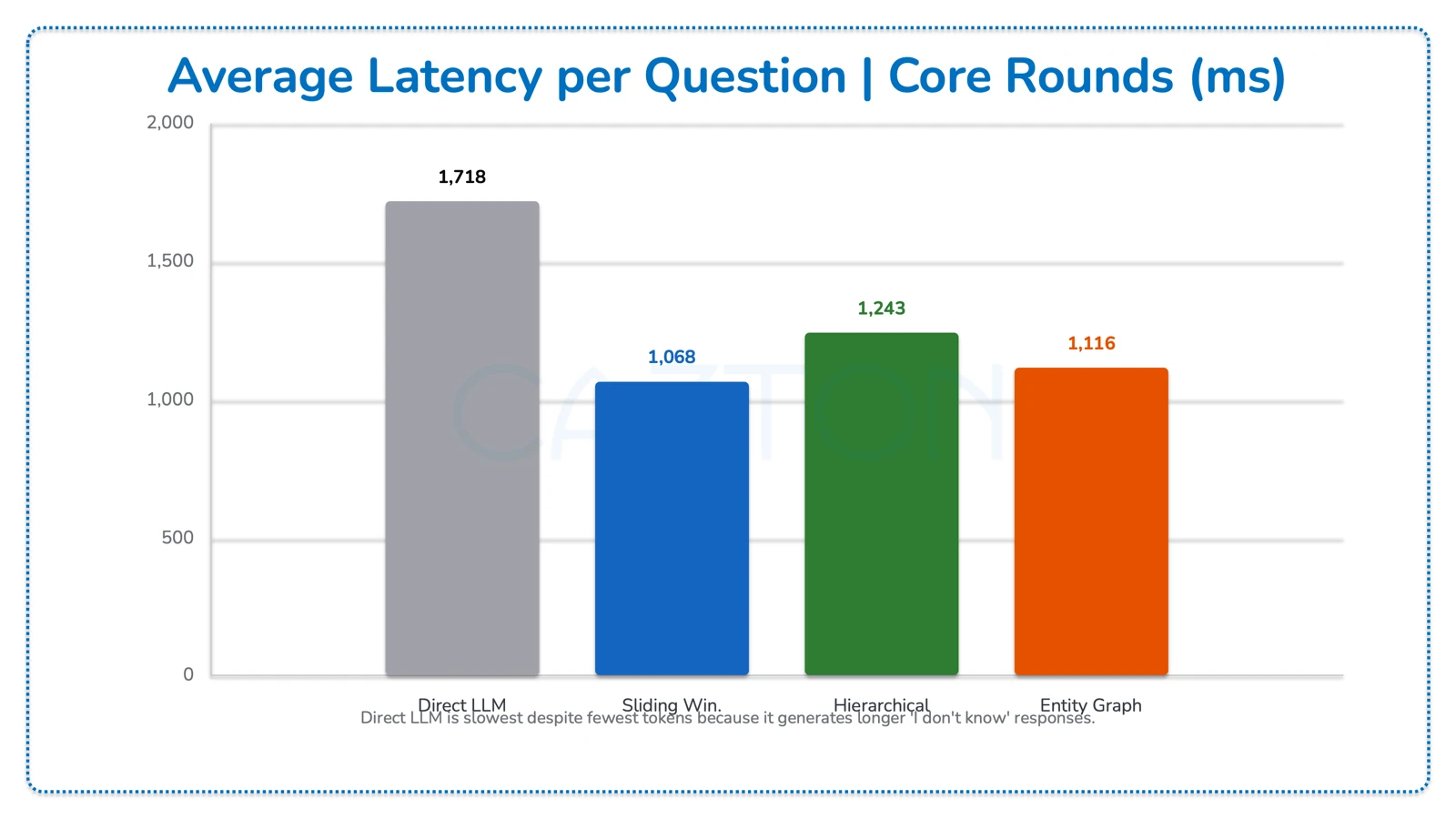
Surprising Finding: Direct LLM has the highest latency despite sending the fewest tokens. Why? Because it sends no context, the model spends more time generating a longer "I don't know" response with suggestions. Memory-backed strategies produce concise, confident answers faster.
When Sliding Window Fails
The sliding window strategy compresses older messages into a rolling summary. When specific details such as URLs, exact names, and niche facts fall outside the 30-message window, they get summarized away.
Example - List Related URLs for the Leadership Profile
We ask for URLs related to https://cazton.com/about/chander-dhall. The consulting URL (/consulting) was mentioned early in the conversation and has since been summarized out of the sliding window.
| Strategy | Result | Response | Notes |
|---|---|---|---|
| Sliding Window | FAIL | "Related Cazton URLs we captured (in the same 'About/Contact' area) are: about-us, contact-us" | Missing: /consulting URL lost during summary compression |
| Hierarchical | PASS | "About Us, Homepage, Contact, consulting" | |
| Entity Graph | PASS | "homepage, about-us, consulting, trainings, workshops, products, ebooks, presentations, videos, contact-us" | 10 URLs recalled - most comprehensive answer |
Example - Profile-Linked URLs Plus Videos and Presentations
| Strategy | Status | Prompt Tokens | Latency | Missing Detail |
|---|---|---|---|---|
| Sliding Window | FAIL | 1,115 | 1,471 ms | Missing /presentations URL |
| Hierarchical | PASS | 1,448 | 1,478 ms | |
| Entity Graph | PASS | 1,455 | 1,306 ms |
Why Sliding Window Fails: The rolling summary is designed to be concise. When the summarizer compresses 30+ messages into a paragraph, it prioritizes the gist over specific URLs like /presentations. The information existed but was lost in compression.
When Both Sliding Window and Hierarchical Fail
This is where Entity Graph truly shines. Some questions require precise recall of specific entity relationships, facts that get lost in any summarization process.
Example - Return Profile-Linked URLs Including Products and Non-Page Asset
This question requires three specific pieces: (1) the leadership profile URL, (2) the products page URL, and (3) a non-page asset URL like the OG image. Both Sliding Window and Hierarchical fail because they cannot reliably surface the /products URL from their compressed memories.
| Strategy | Status | Prompt Tokens | Latency | What Failed |
|---|---|---|---|---|
| Direct LLM | BASELINE | 96-101 | 2,996-3,481 ms | No memory at all |
| Sliding Window | FAIL | 1,072-1,159 | 1,232-1,445 ms | Missing /products + graph context |
| Hierarchical | FAIL | 1,394-1,513 | 1,205-1,683 ms | Missing /products + graph context |
| Entity Graph | PASS | 1,409-1,505 | 1,111-1,229 ms |
Entity Graph Response (Correct)
// From our stored graph context:
1) Leadership profile URL: https://cazton.com/about/chander-dhall
2) Products URL: https://cazton.com/products
3) Non-page asset URL: https://cazton.com/images/common/cazton-cover.webpThe Default Dataset Tells the Same Story
Using the FakeCompany/Placeholder fictional dataset (60-turn conversation), the divergence is even more dramatic:
| Question | Sliding Window | Hierarchical | Entity Graph |
|---|---|---|---|
| Project repository URL? | FAIL | FAIL | PASS |
| Project deadline? | FAIL | PASS | PASS |
| Team lead + preferred language? | FAIL | PASS | PASS |
| Deadline + sponsor name? | FAIL | PASS | PASS |
| Four main frontend views? | FAIL | FAIL | PASS |
Entity Graph - Highest Recall in This Run: In the 10 Cazton rounds shown here, Entity Graph passed all recall checks. Because it stores structured entities instead of relying only on compressed summaries, it reduced summary-loss errors in this run.
Comprehensive Metrics Dashboard
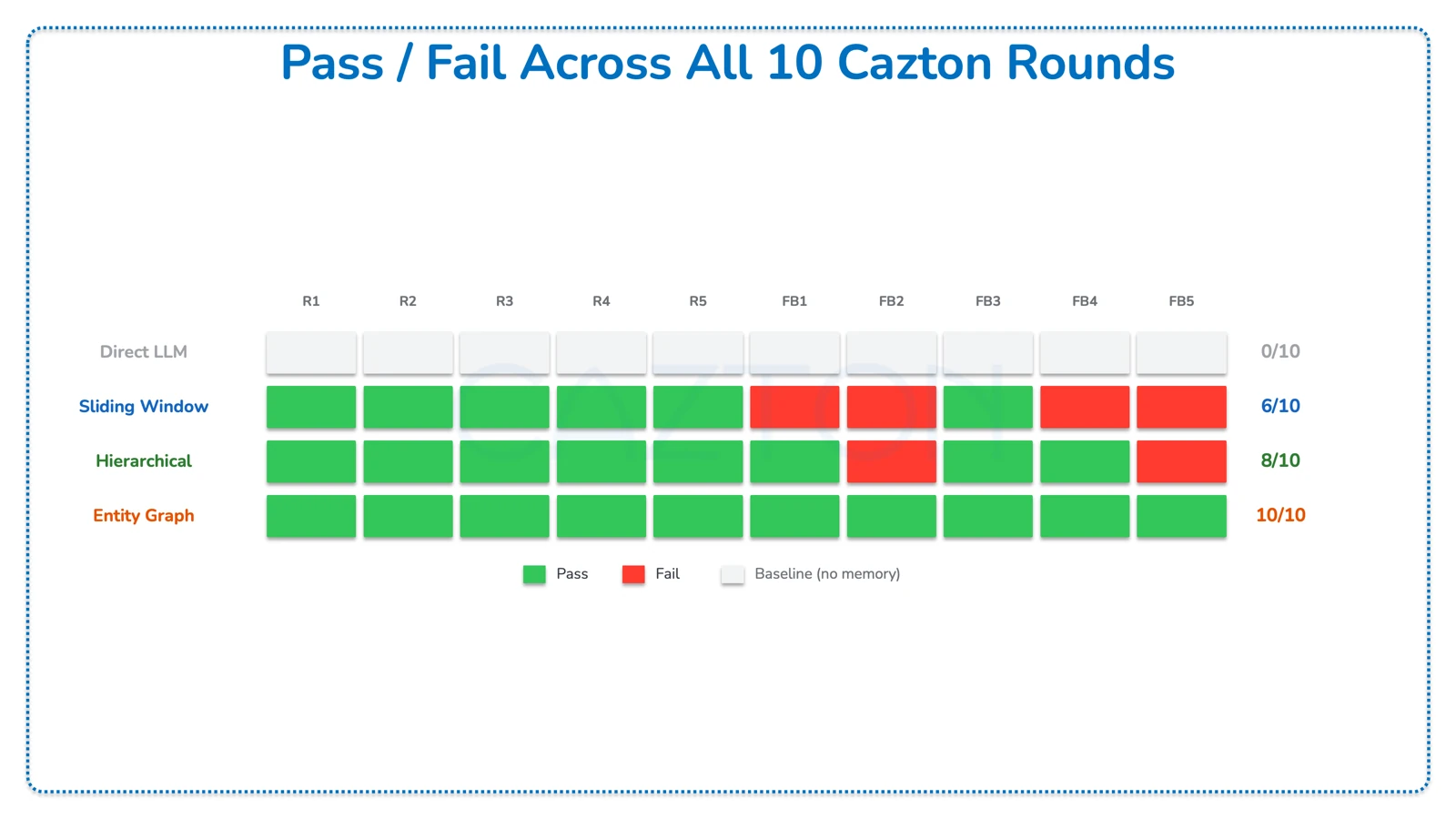
Here is every metric across all 10 Cazton rounds.
Complete Scorecard - All 10 Rounds
Pass/fail results across all 10 Cazton rounds (R1-R5 = core recall questions; FB1-FB5 = fallback/harder rounds):
- Direct LLM: 0/10 - no memory, all rounds scored as baseline
- Sliding Window: 6/10 - passed R1, R2, R3, R4, R5, FB3; failed FB1, FB2, FB4, FB5
- Hierarchical: 8/10 - passed R1, R2, R3, R4, R5, FB1, FB3, FB4; failed FB2, FB5
- Entity Graph: 10/10 - passed all rounds
Strategy Comparison Summary
| Metric | Direct LLM | Sliding Window | Hierarchical | Entity Graph |
|---|---|---|---|---|
| Recall Rate (Cazton) | 0% | 60% | 80% | 100% |
| Avg Prompt Tokens | 92 | 1,100 | 1,397 | 1,656 |
| Avg Latency (ms) | 2,505 | 1,108 | 1,343 | 1,258 |
| Context Window | 1 message | 30 messages | 10 + summaries | 6 + entities |
| Message TTL | None | 1 hour | 6 hours | 6 hours |
| LLM Calls per Turn | 1 | 1-2 | 1-2 | 2-3 |
| Cosmos Containers | 1 | 1 | 1 | 2 |
| Vector Search | No | No | No | Yes |
Cosmos DB Architecture
All four strategies share a common foundation: Azure Cosmos DB for NoSQL with partition key /session_id. The difference is in what they store and how they query.
| Container | Strategy | Document Types | Special Indexes |
|---|---|---|---|
direct_llm_sessions |
Direct LLM | session | None |
sliding_window_sessions |
Sliding Window | session, msg | None |
hierarchical_sessions |
Hierarchical | session, msg, tier2_summary, tier3_facts | None |
entity_graph_sessions |
Entity Graph | session, msg | None |
entity_graph_entities |
Entity Graph | entity (with embedding) | DiskANN vector index on /embedding |
Entity Document Structure
{
"id": "session123::cazton.com",
"session_id": "session123",
"name": "cazton.com",
"type": "organization",
"facts": [
"Consulting, Training, Recruiting",
"One stop shop for AI and custom software",
"Homepage: https://cazton.com/"
],
"related_to": ["Chander Dhall", "Austin", "Dallas"],
"searchText": "cazton.com organization consulting training...",
"embedding": [0.0123, -0.0456, ...] // 1536 dimensions
}Retrieval Modes
- Vector Only:
ORDER BY VectorDistance(c.embedding, @queryVector) - Full-Text Only:
FULLTEXTCONTAINS(c.searchText, @phrase) - Hybrid (RRF):
ORDER BY RANK RRF(FULLTEXTSCORE(...), VectorDistance(...)) - Lexical Fallback:
CONTAINS(c.searchText, @keyword, true)- always runs as a safety net
Methodology
Full transparency on how these benchmarks were run:
- LLM: OpenAI
gpt-5.4(chat, summarization & entity extraction) - Embeddings: text-embedding-3-small, 1536 dimensions
- Temperature: 0 (deterministic outputs)
- Database: Azure Cosmos DB for NoSQL (account: cazton2026)
- Retrieval mode: Vector-only (DiskANN) + lexical CONTAINS fallback. Full-text search (FULLTEXTCONTAINS) and Hybrid RRF were not enabled for these benchmarks.
- Top-K retrieval: Entity Graph retrieves top-6 entities by cosine similarity (VectorDistance), with lexical CONTAINS fallback when vector results are empty.
- Prompt templates: Identical system prompt across all strategies; only the context-assembly method differs.
- Seed data: 60 Cazton fact messages, loaded identically into all 4 strategies
- Measurement: Single run per question (not averaged); latency = client-side wall-clock time for OpenAI API call (warm, not cold start)
- Token counting: Reported by OpenAI usage object (prompt_tokens, completion_tokens)
- Pass/fail criteria: Automated anchor keyword matching (e.g., must contain "/consulting" or "cazton.com/consulting")
- Captured: March 4, 2026 at 21:05:51 UTC
Complete Evidence - All 10 Cazton Rounds
Every question, every strategy, every metric. The full run log (40 rows).
| Round | Question | Strategy | Status | Prompt Tok. | Total Tok. | Latency | Fail Reason |
|---|---|---|---|---|---|---|---|
| R1 | Three headline offerings? | Direct LLM | BASELINE | 93 | 149 | 1,743ms | |
| Sliding Window | PASS | 1,335 | 1,360 | 826ms | |||
| Hierarchical | PASS | 1,307 | 1,351 | 1,012ms | |||
| Entity Graph | PASS | 1,773 | 1,817 | 1,058ms | |||
| R2 | Leadership profile URL? | Direct LLM | BASELINE | 92 | 139 | 1,639ms | |
| Sliding Window | PASS | 1,334 | 1,358 | 812ms | |||
| Hierarchical | PASS | 1,343 | 1,373 | 920ms | |||
| Entity Graph | PASS | 1,885 | 1,915 | 926ms | |||
| R3 | Cosmos video & ebook slugs? | Direct LLM | BASELINE | 94 | 148 | 1,314ms | |
| Sliding Window | PASS | 981 | 1,049 | 2,003ms | |||
| Hierarchical | PASS | 1,368 | 1,403 | 1,219ms | |||
| Entity Graph | PASS | 1,479 | 1,517 | 977ms | |||
| R4 | Contact & workshops paths? | Direct LLM | BASELINE | 89 | 153 | 1,770ms | |
| Sliding Window | PASS | 1,026 | 1,050 | 928ms | |||
| Hierarchical | PASS | 1,388 | 1,412 | 2,202ms | |||
| Entity Graph | PASS | 1,885 | 1,908 | 1,821ms | |||
| R5 | Canonical URL & OG image? | Direct LLM | BASELINE | 90 | 186 | 2,122ms | |
| Sliding Window | PASS | 1,026 | 1,054 | 770ms | |||
| Hierarchical | PASS | 1,404 | 1,432 | 864ms | |||
| Entity Graph | PASS | 1,908 | 1,936 | 719ms | |||
| FB1 | Related URLs for profile? | Direct LLM | BASELINE | 93 | 376 | 4,925ms | |
| Sliding Window | FAIL | 1,042 | 1,087 | 1,505ms | Missing /consulting | ||
| Hierarchical | PASS | 1,345 | 1,406 | 1,464ms | |||
| Entity Graph | PASS | 1,290 | 1,419 | 2,189ms | |||
| FB2 | Profile + products + asset? | Direct LLM | BASELINE | 96 | 262 | 2,996ms | |
| Sliding Window | FAIL | 1,072 | 1,134 | 1,445ms | Missing /products | ||
| Hierarchical | FAIL | 1,394 | 1,479 | 1,683ms | Missing /products | ||
| Entity Graph | PASS | 1,505 | 1,565 | 1,229ms | |||
| FB3 | Training URL? | Direct LLM | BASELINE | 83 | 158 | 1,590ms | |
| Sliding Window | PASS | 1,109 | 1,131 | 1,056ms | |||
| Hierarchical | PASS | 1,456 | 1,469 | 1,586ms | |||
| Entity Graph | PASS | 1,966 | 1,988 | 1,107ms | |||
| FB4 | Profile + videos + presentations? | Direct LLM | BASELINE | 90 | 257 | 3,931ms | |
| Sliding Window | FAIL | 1,115 | 1,164 | 1,471ms | Missing /presentations | ||
| Hierarchical | PASS | 1,448 | 1,512 | 1,478ms | |||
| Entity Graph | PASS | 1,455 | 1,498 | 1,306ms | |||
| FB5 | Profile + products + asset (graph)? | Direct LLM | BASELINE | 101 | 256 | 3,481ms | |
| Sliding Window | FAIL | 1,159 | 1,214 | 1,232ms | Missing graph context | ||
| Hierarchical | FAIL | 1,513 | 1,585 | 1,205ms | Missing graph context | ||
| Entity Graph | PASS | 1,409 | 1,469 | 1,111ms |
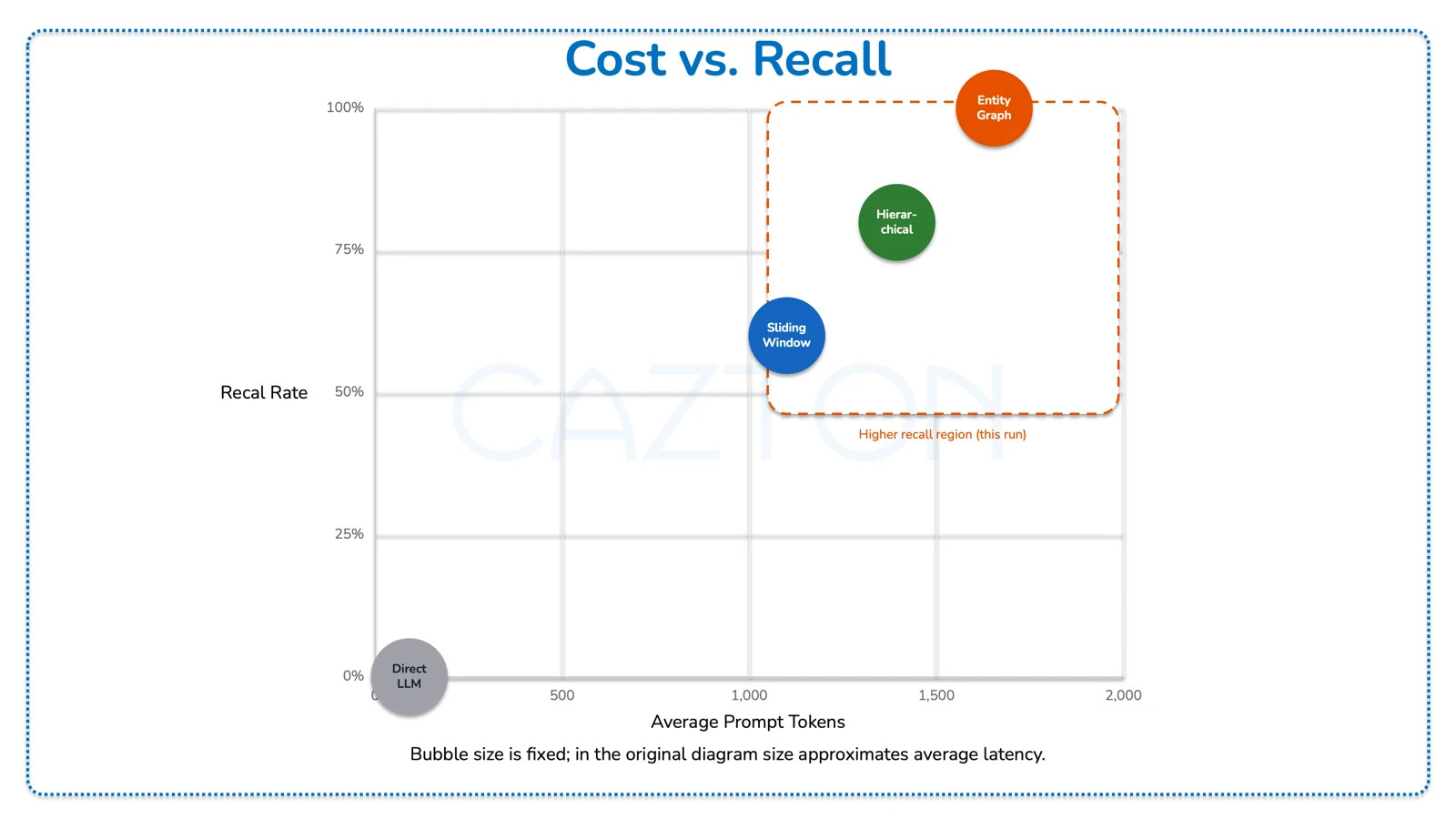
Cost vs. Recall - Executive View
The following table shows the four strategies plotted by average prompt token cost against recall rate in this run. Bubble size in the original diagram corresponds to average latency.
| Strategy | Avg Prompt Tokens | Recall Rate | Avg Latency (ms) |
|---|---|---|---|
| Direct LLM | 92 | 0% | 2,505 |
| Sliding Window | 1,100 | 60% | 1,108 |
| Hierarchical | 1,397 | 80% | 1,343 |
| Entity Graph | 1,656 | 100% | 1,258 |
In this run, Entity Graph reached 100% recall at ~1,656 avg prompt tokens. Sliding Window used ~1,100 tokens with 60% recall. Higher-recall strategies are clustered in the upper-right region of the cost/recall space.
Conclusion
There is no single best strategy. The right choice depends on your requirements for recall precision, token budget, and implementation complexity. Match your memory architecture to your application's needs.
Direct LLM - Stateless Queries
One-shot Q&A, code generation, and translation are tasks where prior context is irrelevant. Lowest cost, zero infrastructure.
Sliding Window - Short Conversations
Best suited for customer support chats and quick troubleshooting sessions where conversations stay under 30 turns and recent context matters most. Lowest prompt-token use among memory-enabled options in this run.
Hierarchical - Medium-Length Workflows
Best suited for project planning and multi-session consultations where key facts need to persist across 30 to 100 turns. Good balance of recall and cost.
Entity Graph - Long-Running Agents
Best suited for enterprise assistants, knowledge workers, and CRM-integrated bots where high identifier-level recall matters and conversations span many turns. Highest recall in this run, with more implementation overhead.
The Bottom Line
| Dimension | Winner | Why |
|---|---|---|
| Lowest Token Cost | Sliding Window | ~1,100 prompt tokens avg - 33% less than Entity Graph |
| Fastest Latency | Sliding Window | ~1,068 ms avg - fastest for simple recall |
| Best Recall | Entity Graph | 100% recall in this run (10/10); do not assume universal performance without local validation |
| Best Balance | Hierarchical | 80% recall with moderate token cost |
| Simplest Implementation | Direct LLM | ~60 lines of code, no memory management |
Final Thought: Memory is not just a feature; it is a spectrum. Start with the simplest strategy that meets your recall requirements, and upgrade when your users' conversations demand it. In this reference implementation, all four strategies share the same partition key (/session_id), SDK, and operational model. Moving from Sliding Window to Entity Graph can be handled as an application-layer change instead of an infrastructure migration.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.