AI That Ships and AI That Stalls
- Governance is the blocker: Most GenAI pilots fail on last-mile delivery, not model quality.
- “Receipts” beat slideware: Success definitions, eval plans, security maps, and production gates separate demos from production.
- Common failure modes are fixable: Missing KPIs, weak data contracts, no workflow integration, unowned risk, and no adoption plan.
- Budget for the last mile: Integration, monitoring, rollback, and operational handoff determine whether pilots ship.
- Top clients: At Cazton, we help Fortune 500, large, mid-size and startup companies with Big Data and AI development, deployment (MLOps), consulting, recruiting services and hands-on training services. Our clients include Microsoft, Google, Broadcom, Thomson Reuters, Bank of America, Macquarie, Dell and more.
- Microsoft and Cazton: We work closely with OpenAI, Azure OpenAI, Azure Cosmos DB and many other Microsoft teams. Thanks to Microsoft for providing us with very early access to critical technologies. We are fortunate to have been working on GPT-3 since 2020, a couple years before ChatGPT was launched.
- Trusted by industry leaders: Join Microsoft, Google, Broadcom, Charles Schwab, CVS and other Fortune 500 companies who rely on our expertise for mission-critical AI automation implementations.
A recurring pattern in enterprise GenAI: many pilots don’t reach durable, measurable production value. The exact failure rate varies by study and definition, but the failure modes repeat with consistency.
For teams shipping real systems, this is not surprising. It is a often a governance and last-mile problem more than a model problem.
The more interesting development is what happened after the failure-rate headlines: decision-making in many organizations got more disciplined.

The Shift: When "AI" Became a Higher-Scrutiny Topic
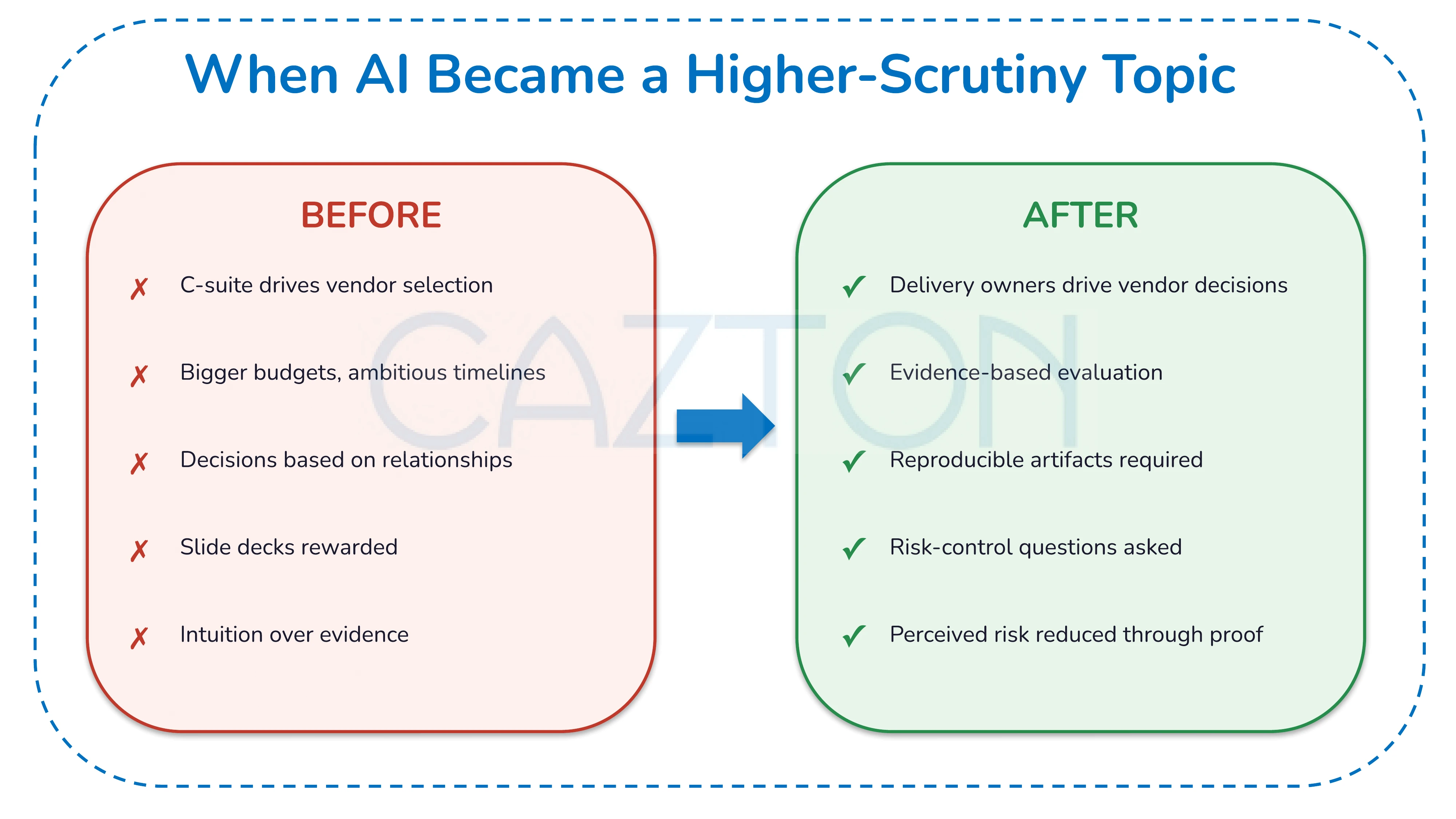
Before the wave of failure-rate coverage, many C-suite leaders were eager to launch AI initiatives. Often: bigger budgets, ambitious timelines, and vendor relationships already in place.
After the headlines, many executives paused public enthusiasm and asked for more proof.
Instead, we started hearing from engineering managers, technical leads, data science directors, and senior developers - people closer to the actual delivery.
The pattern was simple:
Executives wanted to reduce perceived risk. Less intuition, more evidence.
But the pressure to "do something with AI" did not disappear. So the work moved to the people who can actually ship it - engineering, data, security, and product teams.
That shift is healthy when it brings both accountability and the right gates.
The Twist: Better Decisions Came From the Delivery Owners
Here is what many organizations did not anticipate: the people doing the work often made more delivery-informed vendor selection decisions.
Why?
They knew how to vet with technical rigor.
Many of these technical leads and engineering managers grew up with GitHub. They use LLMs daily. They have learned to leverage AI tools to research companies, analyze case studies, and dig into technical implementations.
Slide decks aren’t enough. They look for reproducible evidence.
They ask questions that force real artifacts:
- "Show me your evaluation plan (offline + in production) and how it maps to a business KPI."
- "When do you choose RAG vs. fine-tuning - and what breaks in each approach?"
- "How do you test retrieval quality and control cost/latency at scale?"
- "Show me deployment, rollback, monitoring, and on-call ownership."
- "What is your architecture and dependency strategy, and how do you handle framework churn?"
These aren’t flashy questions. They are risk-control questions.
Why Pilots Stall - and What Predicts Success
The projects that succeed tend to share one trait: they are measured by production artifacts - gates, controls, integration, adoption - not demo theatrics.
The projects that stall usually fail in the same places. Regardless of which study you cite, the recurring reasons are consistent - and fixable.
Most "failures" are not model failures. They are delivery failures:
- No success definition: KPI, owner, and decision/workflow change are undefined.
- No evaluation strategy: No baseline, no test set, no definition of "what good looks like," and no production monitoring.
- Weak data contracts: Inputs drift, permissions are unclear, lineage is missing.
- No workflow integration: The model lives in a sandbox instead of the real system of record.
- Unowned risk: Security, compliance, privacy, retention, and audit evidence are not mapped.
- No adoption plan: Training, feedback loops, and iteration cadence are absent.
To be clear: failed AI projects are bad for teams and for broader confidence in the space. They waste resources, discourage teams, and create skeptics. This is not about celebrating anyone's missteps.
It highlights a disconnect between buying and shipping.
Teams with repeatable playbooks - whether internal or via a partner - tend to ship more often because they have already paid the tuition on the last mile. The advantage is unglamorous: fewer unknown unknowns, better gates, and cleaner escalation paths.
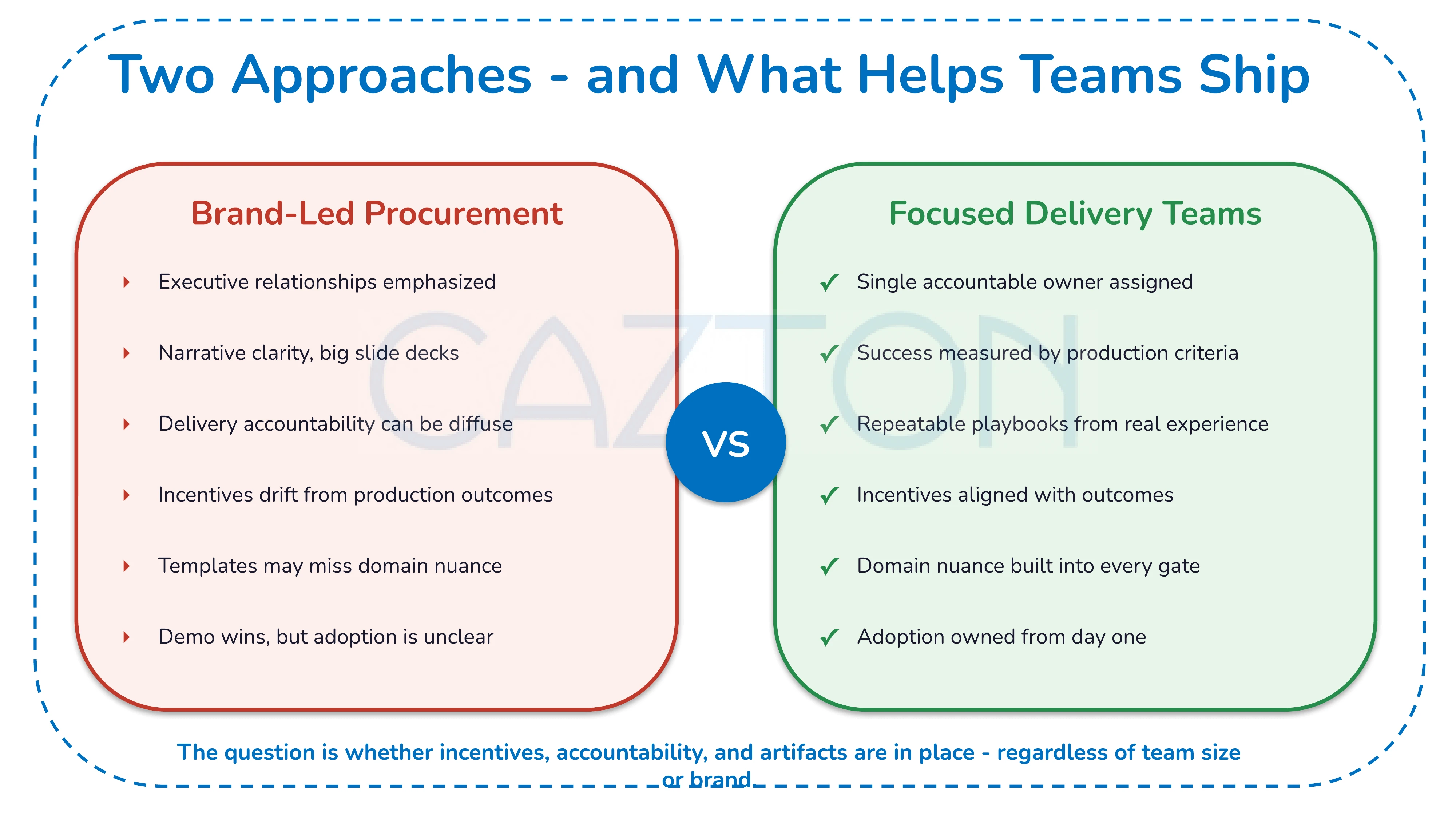
Two Approaches (and What Helps Teams Ship)
Brand-led procurement often emphasizes executive relationships and narrative clarity - but delivery accountability can be diffuse, incentives can drift from production outcomes, and templates may miss domain nuance. Focused delivery teams, by contrast, assign a single accountable owner, measure success by production acceptance criteria, and use repeatable playbooks built from real integration experience. Neither approach is inherently right or wrong - the question is whether incentives, accountability, and artifacts are in place regardless of team size or brand.
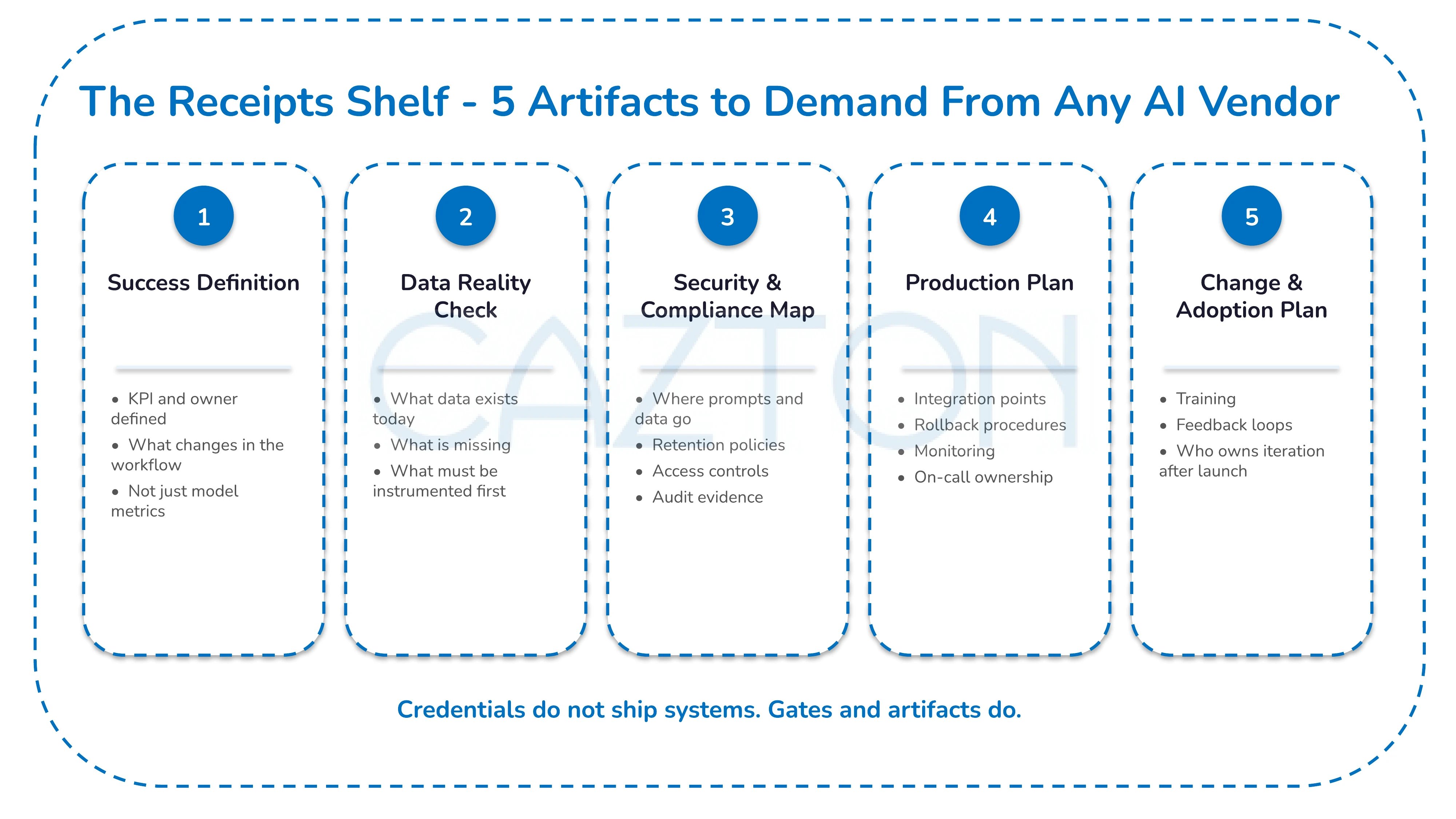
What to Ask Any Vendor (The "Receipts Shelf")
If you want to avoid pilot purgatory, ask for these artifacts up front:
- Success definition (one page): KPI, owner, and "what changes in the workflow" - not just model metrics.
- Data reality check: What data exists, what is missing, and what must be instrumented before anything else.
- Security and compliance map: Where prompts and data go, retention policies, access controls, and audit evidence.
- Production plan: Integration points, rollback procedures, monitoring, and on-call ownership.
- Change and adoption plan: Training, feedback loops, and who owns iteration after launch.
At Cazton, our bias is defensible claims over hype. We walk you through how we run discovery, gates, QA, security, and production hardening - because process is the most reliable proof.
Where confidentiality allows, we share relevant evidence. Otherwise, we use a proof path: redacted sample → small paid pilot → expand.
Credentials do not ship systems. Gates and artifacts do.
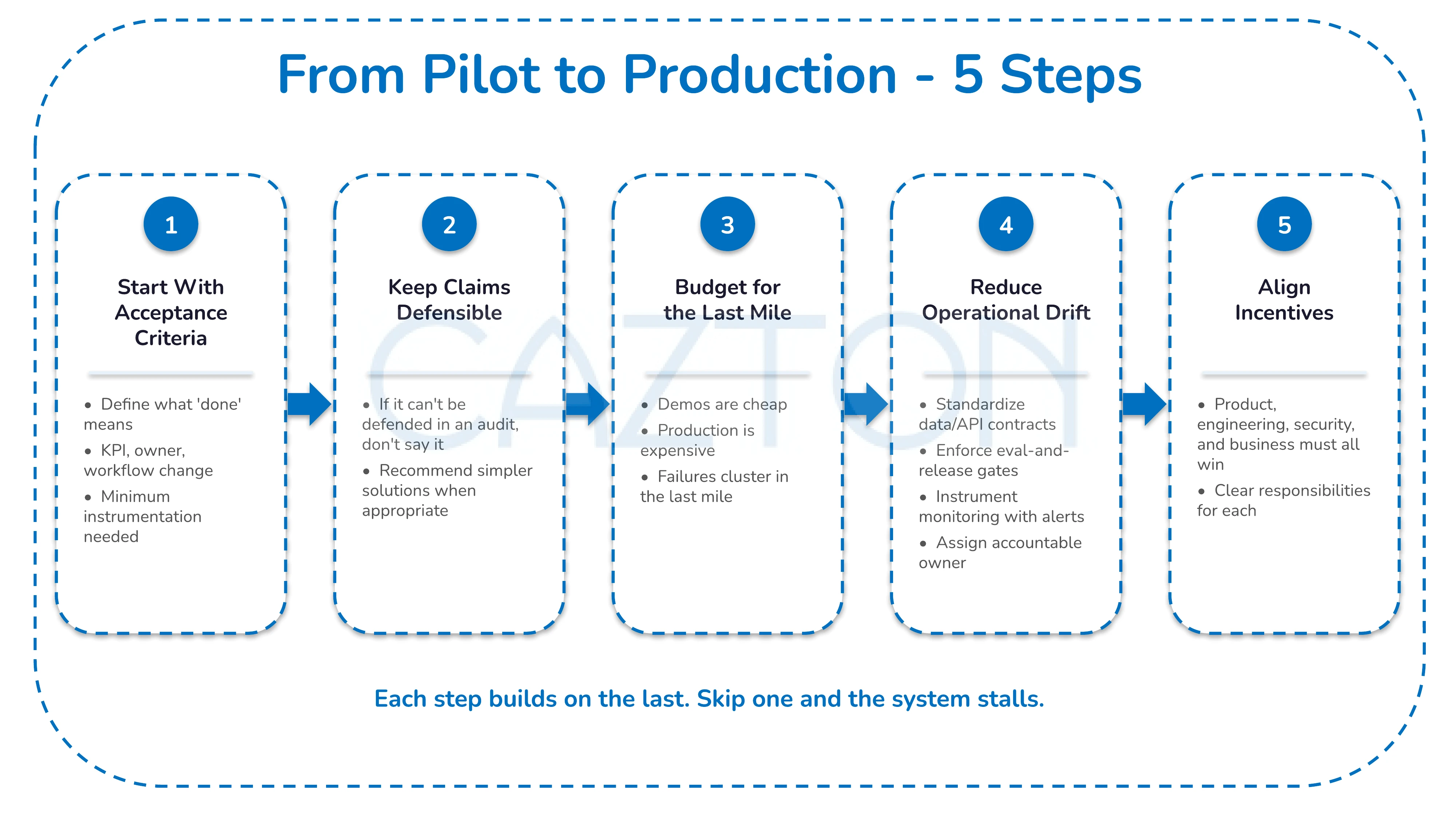
How We Approach the Work
1. We start with acceptance criteria
A common pattern in stalled AI projects is that organizations try to force AI into workflows that were not designed for it.
We start by defining what "done" means:
- What decision or workflow changes if this works?
- What KPI moves, and who owns that KPI?
- What data exists today, and what is the minimum instrumentation needed?
- Where will humans stay in the loop, and what are the guardrails?
- Who will run it after go-live (on-call, monitoring, iteration)?
2. We keep claims defensible
If AI is not the right solution, we say so. If a simpler automation approach would work better, we recommend it. If the data is not ready, we explain what needs to happen first.
Principle: if it cannot be defended in an audit, do not say it.
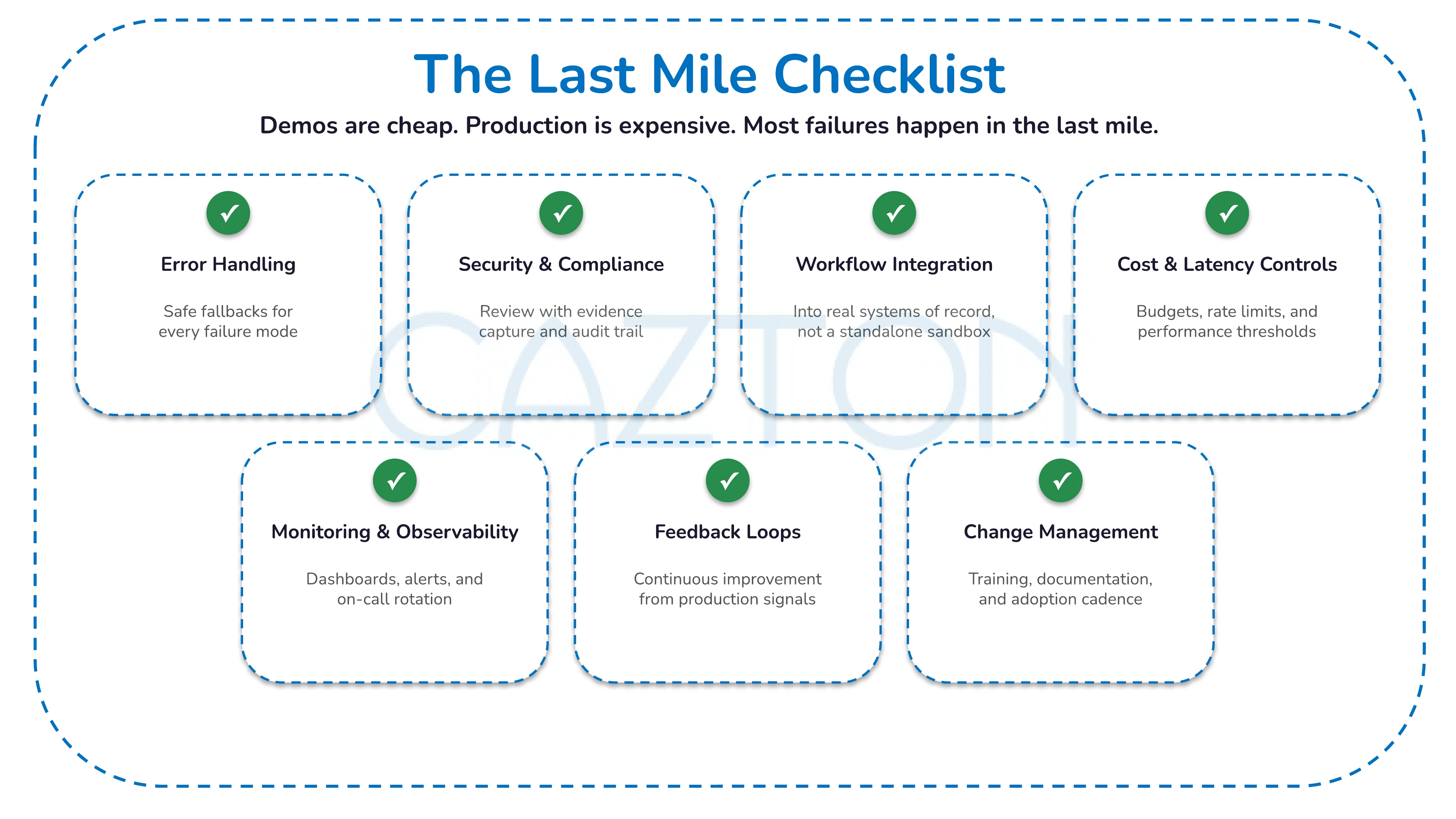
3. We budget for the last mile
Demos are cheap. Production is expensive. Failures disproportionately cluster in the last mile - integration, adoption, and operational handoff.
Our last-mile checklist covers everything that must exist before a system is production-ready:
- Error handling and safe fallbacks
- Security and compliance review with evidence capture
- Integration into real workflows (not a standalone tool nobody uses)
- Latency and cost controls
- Monitoring, observability, and on-call rotation
- Feedback loops and continuous improvement
- Change management and training
This is where documented playbooks, post-mortems, and production checklists reduce risk. Teams with established runbooks and prior production incident learnings can often reduce rework and shorten the path to production compared to teams building the muscle for the first time.
4. We reduce operational drift (so the system remains maintainable over time)
GenAI stacks change fast. The way you prevent "pilot rot" is to prevent pilot rot by standardizing data/API contracts, enforcing an eval-and-release gate, instrumenting cost/latency/quality monitoring with alerts, and assigning a single accountable owner with runbooks and on-call coverage.
If the project does not have an owner, an on-call rotation, and a cadence for iteration, it is likely to stall - even if the demo worked.
This is why teams with repeatable playbooks - whether internal or via a partner - ship more often: fewer unknowns, fewer surprises, fewer late-stage rewrites.
5. We align incentives (so value actually lands)
If incentives are not aligned, you get theater: demo wins, but nobody owns adoption.
Production value only happens when product, engineering, security, and the business owner all win - and each has clear responsibilities.
That is why we bias toward the less exciting work: success definitions, controls, and evidence.
A Message to Technical Leads, EMs, and Senior ICs
If you think you are not senior enough to influence outcomes, consider this: gates - such as eval plans and security reviews - are one of the strongest levers technical leads can use.
You can require artifacts before any pilot moves forward.
When you demand proof - an eval plan, a security map, a production plan - you prevent wasted quarters and broken trust.
Teams that ship reliably tend to have someone insisting on substance over theater.
Your job is not to "believe in AI." Your job is to control risk and land value.
Start with one change: insist on acceptance criteria before any pilot begins.
A Message to Teams Building GenAI Solutions
If you build GenAI systems for a living, your edge is not the demo. Teams that invest in the last mile - evals, runbooks, rollback plans, and post-mortems - tend to build more defensible proof.
You win by being the most operationally trustworthy.
You do not need a giant brand to win deals. You need defensible proof.
Ship the artifacts: evals, runbooks, rollback plans, and post-mortems.
The work is hard because it is systems engineering, not prompt engineering.
When you get it right, you do not just ship a feature. You ship trust.
And that reputation compounds.
The Path Forward
Enterprise AI is not going away. The pressure to implement is intensifying.
Teams that add gates and artifacts to their pilot plans tend to ship more reliably.
For Organizations
- Empower your technical leaders to make vendor decisions
- Value demonstrated expertise over brand recognition
- Demand measurable outcomes, not impressive demos
- Budget for the last mile that separates POCs from production
- Choose partners who own accountability, not just relationships
For Technical Professionals
- Trust your ability to evaluate vendors and solutions
- Ask hard questions and demand real answers
- Use the tools at your disposal (LLMs, GitHub, technical communities) to research and vet
- Your judgment and expertise are valuable - exercise them
For AI Solution Providers
- Focus on outcomes, not sales
- Build deep expertise in specific domains
- Own accountability for results
- Be honest about what AI can and cannot do
- Invest in continuous learning for your team
The future of enterprise GenAI belongs to teams who treat it like any other high-scrutiny system: clear requirements, controlled risk, evidence, and iteration.
Success is not size. It is reliability.
A sample pilot-readiness checklist - covering gates, evidence, and rollback - is available on request.
Chander Dhall is the CEO of Cazton and a multi-time Microsoft AI MVP (recognized in 2025 as a Microsoft AI MVP in the U.S.). Cazton helps enterprises move from pilot to production with defensible delivery: gates, evidence, and operational ownership.
What has been your experience with AI projects? Are vendor decisions being made based on technical capability or brand recognition? Share your thoughts in the comments.
Contact us to discuss your GenAI roadmap.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.