Apache Ignite Consulting
- Apache Ignite is an open source distributed database, caching and processing platform which handles petabytes of data with in-memory speed.
- It offers fault tolerance, cluster wide pub/sub messaging, dynamic rebalancing of the clusters in case of failures, in-memory file system, data-grid, database, streaming analytics. It can be used to solve scalability and performance problems.
- At Cazton, we help Fortune 500, large and mid-size companies with Apache Ignite best practices, development, performance tuning, consulting, recruiting services and hands-on training services.
In-Memory Computing Platform
Do you face problems while scaling data in memory? Are you facing slow processing times? Do you want scalability and as well as atomic transactions? Do your machine learning models require a lot of time for training and production? Are you looking for SQL ACID transactions in distributed computing environment? Recently, Ignite processed 2.5 TB in production flawlessly.
Wait no further, here is the solution. Apache Ignite is an open source distributed database, caching and processing platform which handles terabytes of data with in-memory speed. The difference between Ignite and a classic distributed cache is that, with Ignite in addition to key-value pairs we can run distributed SQL queries for joining and grouping various data sets. Even with distributed SQL queries, we can execute multi-record and cross-cache ACID transactions, with the help of shared or unified in-memory layer. Some of the other features that come up with Apache Ignite are:
- Has fault tolerance and supports full ACID transactions.
- Uses publish/subscribe(pub/sub) cluster wide messaging, which is a form of asynchronous service-to-service communication and used in serverless and microservices architectures.
- Dynamic rebalancing of the clusters in case of failures.
- In-memory file system, data-grid, database, streaming analytics, and a continuous learning framework for machine and deep learning.
- Event driven architecture in memory.
- Help solve scalability and high-performance issues, supports advance real-time performance.
- Plug in NOSQL, MongoDb database.
- Supports Big Data, Machine Learning
Contact us now to know more about Apache Ignite's capabilities as a distributed database and in-memory computing. Now that we have a good overview about what Ignite is, let's deep dive into it.
Apache Ignite can be utilized as a:
- In-Memory Cache: It supports key-value and ANSI SQL with low latency and high performance in memory cache. It can be deployed as:
- Cache-aside deployment: Useful when the cache is static and not updated much. The cache is deployed the from primary data store and the application is responsible for data-synchronization in the primary data store and replication in cache.
- Read Through / Write Through Caching: Useful for architectures that would like to create a shared caching layer across many disconnected data sources or to accelerate existing disk-based databases. This type of strategy is a type of In-Memory Data Grid deployment, where applications read and write to Ignite, and in turn Ignite makes sure that any underlying external data remains consistent and updated with the in-memory data.
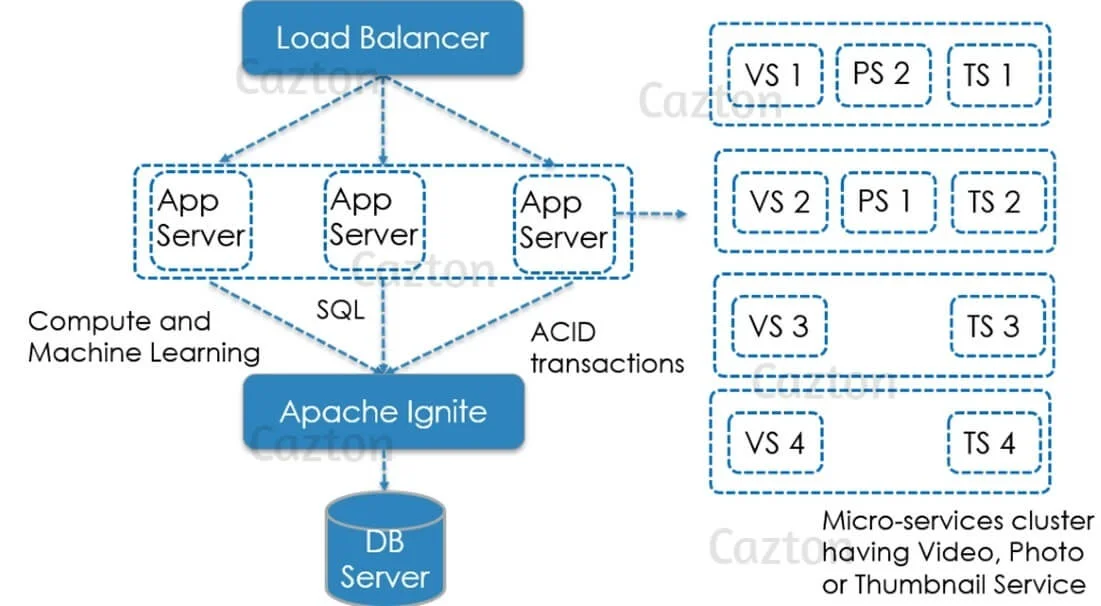
- In-Memory Data Grid: It is used in the Read / Write through cache deployment. It can be used purely in-memory or with native persistence. It can be used on top of RDBMS, Hadoop and other data sources to gain 100x acceleration, by sliding in between application and database layer as an in-memory data grid.
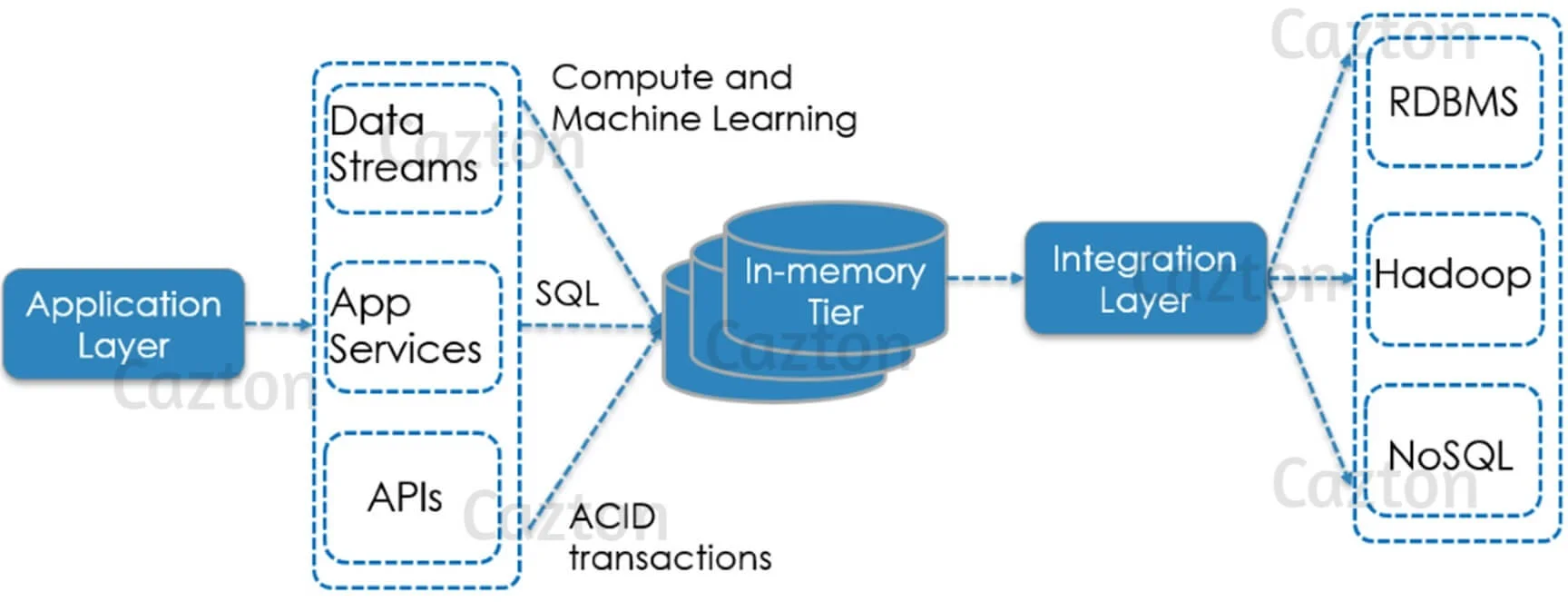
- In-Memory Database: It is used in distributed multi-tier storage to scale out and up across RAM, NVRAM, Flash, and disk. Ignite becomes fully operational from disk without requiring preloading from a memory tier. It uses co-located processing which reduces the network traffic by using SQL with JOINs on the distributed data. Each Ignite server node allocates the memory regions during bootstrapping phase, splits them into pages, and keeps the data records with indexes in those pages. Furthermore, disk persistence can be disabled when required and then it will act as a pure in-memory database.
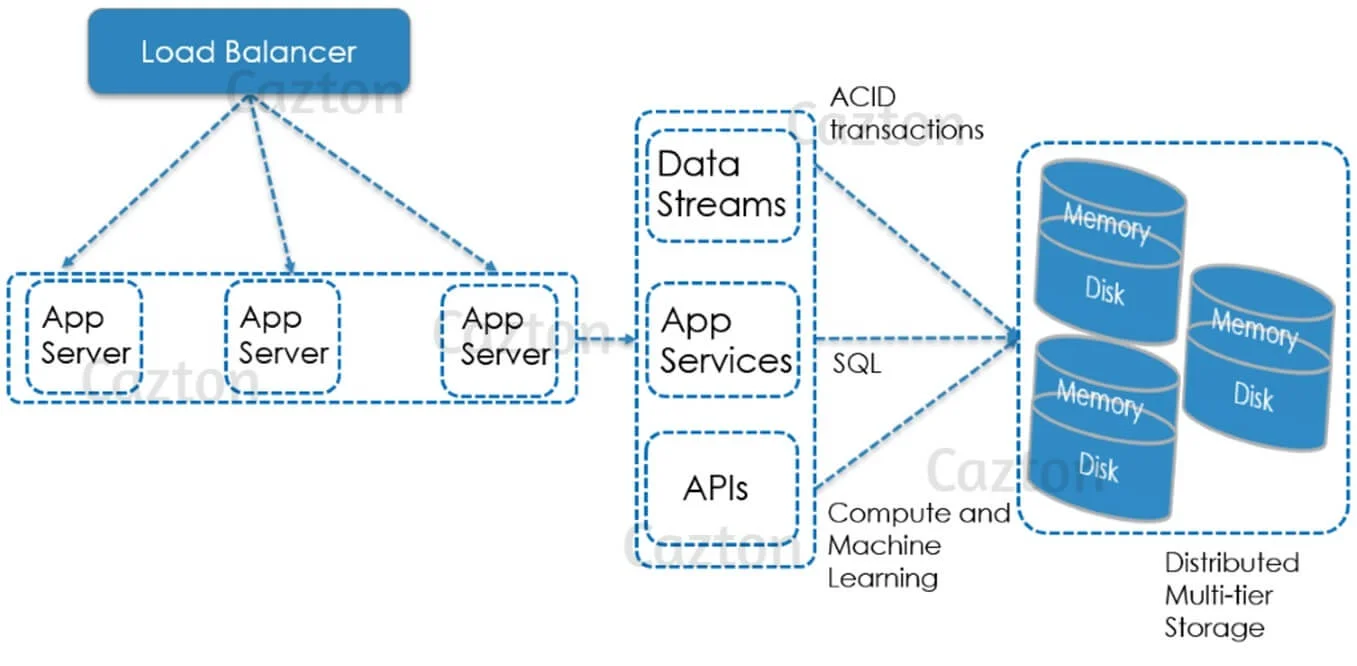
Ignite also acts as a Digital Integration Hub by enabling large-scale and high-throughput architectures. This avoids complex integrations between back-end databases and front-end API services. It can support both uni-directional and bi-directional synchronization between an Ignite cluster and an external store database using Kakfa, Spark or Debezium.
It offers data grid capability - partition and caching data capability in memory. Each cache represents an entity of the database and can be split into a fixed set of partitions evenly distributed among cluster nodes. There is always a primary partition and can have its zero or more backup copy partitions.
Ignite is 100% JCache (JSR 107) compliant in-memory data grid which includes basic cache get/put operations, Concurrent Map APIs, Entry Processor and Cache Interceptor APIs, events and metrics. For applications which requires consistent response time ranging in microseconds, the 'near cache' of Ignite can be used to store the most frequently used data on the application end. It automatically invalidates and updates the near cache. Once a change is made to the primary copy of a record, Ignite will immediately propagate the change to all the nodes. This includes the nodes which store the backup as well as to the applications which store the record copy in the near cache.
Database components of Ignite scales horizontally in such a way that every node in a cluster hold a portion of key-value pairs using a hash function. The data is rebalanced automatically when a node is added / removed from the cluster, in order to spread the workload and achieve an even data distribution.
The nodes of the cluster are divided into:
- Server / Data nodes: They act as storage and computational units of the cluster and process the incoming requests. They store data and indexes and are responsible for computations.
- Client nodes: They are usually embedded in application code using native libraries written in Java, C# or C++. For other languages and tools Ignite offers SQL APIs exposed via ODBC, JDBC and REST drivers to work with the database. They act as a connection between applications or services to the distributed databases for co-located SQL Joins or any other complex calculations.
A co-located join (which are basically tables joined on partitioning column) avoids data shuffling between nodes and minimizes network usage because the calculations are done on local datasets of the cluster nodes. To use co-located processing, the datasets are co-located by storing the related records on the same cluster nodes (called as affinity co-location). The application will execute a query and Ignite will get the records from both memory and disk automatically. In case of a cluster restart, Ignite will read the data and index from the disk avoiding any potential downtimes.
Is Apache Ignite Totally In-Memory Model?
Memory architecture of Apache Ignite is composed of two storage tiers, aka, "durable memory" - memory and disk tier. It is fully operational from the memory tier, but it can store the data on the disk too, hence making it durable. If the data is large, then memory tier caches as much data depending on the capacity. For example, if there are 100 entries in database and the capacity of memory tier is 40, then 100 are stored in the disk and only 40 of them will be cached. In case of a cache-miss, ignite reads it from the disk automatically regardless of the API, whether you use SQL, key-value or scan queries.
It uses a model like virtual memory of Unix by using paging for memory space management and data reference. However, the indexes here on the whole data-set are stored on the disk (assuming the disk tier is enabled) instead storing them on disk only when it runs out of RAM (for swapping).
Can Ignite Be ACID Compliant and at the Same Time Follow the CAP Theorem?
Short answer is "No". As Ignite is distributed system, CAP theorem does apply. Long answer depends on the context it is being used in. Database systems designed with traditional ACID properties such as RDBMS choose consistency over availability, whereas systems designed around the BASE philosophy, common in the NoSQL movement, choose availability over consistency. It follows from the CAP (Consistency, Availability and Partition tolerance) theorem that at a time of partition, one must choose between consistency and availability.
In transactional mode, you can get consistency with full ACID compliant transactions. On the other hand, In atomic mode, you benefit from the speed and availability. Interestingly, we can mix both modes in your application, by having a few ACID batch-sets and then a few atomic mutations.
How Does It Support ACID Properties?
Ignite supports all DML commands including SELECT, UPDATE, INSERT and DELETE queries, in addition to a subset of DDL commands related to distributed systems. It supports primary and secondary indexes, although the uniqueness being enforced only on the primary index. However, it does not support foreign key constraints, which is primarily to avoid broadcasting messages to each cluster for an update (doing so could have affected performance and scalability).
All the transactions are ACID-compliant and span multiple cluster nodes and caches for both 'memory' and 'disk' tiers. This requires the transactional engine to have some functionality to handle data in failed transactions to avoid causing inconsistencies in the cluster. It uses the two-phase commit (2PC) protocol for these distributed systems to ensure ACID properties. Two-phase commit consists of a commit-request phase (or voting phase) where it votes to commit or abort the transaction, and second being the commit phase where it decides its action based on the voting done in previous phase. So, Ignite keeps the transactions in a local transaction map until they are committed, after which the data is transferred to the participating remote nodes.
Is It Necessary to Use the 2PC Protocol in Ignite?
No, users can configure the system to relax the two-phase commit protocol and enjoy all the performances of an "eventually consistent" solution. The ability to configure the full transactional behavior of database or to forego some consistency for performance makes it more flexible.
Following ACID guarantees are supported by Ignite:
- Committed transactions always survive failures.
- A cluster can always be recovered to the latest committed transaction.
It uses the write-ahead-logging (WAL) technique of storing changes in database, where the changes are first stored in logs on a stable storage, before they are written to the database. Now the changed (dirty) page is copied to the partition files by the 'checkpointing process'. The purpose of WAL is to propagate updates to disk in the fastest way and provide a mechanism supporting full cluster failures. As the WAL grows, it periodically gets checkpointed to the main storage.
Is Ignite a Pure In-Memory Database or Persistent Too?
Well, it's both, and can be turned on and off as required. Ignite's Native Persistence feature when used as a key-value store setting, caches the data in memory and persists it to the disk rather than writing it to an external database. This feature enables it to skip the cache warming step as well as to skip the data reloading phase from external databases. Additionally, the feature always keeps a copy of data on disk, so that you can cache a subset of records anytime you like. If native persistence is used, and a cluster or an individual node goes down in middle of the transaction, it ensures data consistency. Native persistence uses write-ahead-logging (WAL) which ensures all changes are written to a log before they are persisted to the disk.
Apache Ignite supports data preprocessing and model quality estimation with natively implemented classical training algorithms such as Linear Regression, Decision Trees, Random Forest, Gradient Boosting, SVM, K-means and others. It also integrates TensorFlow to allow training neural networks while using data stored on single or distributed node. It uses the MapReduce approach, which avoids node failures and data rebalances, to perform distributed training and make inferences instantly.
Can It Handle Big Data and Apply Machine Learning?
Yes, it can handle both. Machine learning requires a lot of data movement across the network and data scientists are often troubled due to the constant data movement and the lack of horizontal scalability. First, they would have to fetch the data to a system such as Apache Mahout or Apache Spark for training purposes. The whole process involves moving terabytes of data and can significantly increase compute time. Second, large data sets can be trained using Apache Spark and TensorFlow, but that is just a part of a problem. They must deploy the models in production too.
Ignite's multi-tier storage comes to the rescue for both problems. It allows users to run Machine Learning model training and inference directly on the data stored across memory and disk in an Ignite cluster. With the in-house optimized algorithms for co-located distributed processing, they provide in-memory speed and unlimited horizontal scaling when running in place. This way it enables continuous learning that improves decisions in real-time. All the process is fault-tolerant, which means in case of a node failure, learning process won't be interrupted and we will get the results similar to the case when all nodes were up and running.
It can be deployed on the cloud services (such as AWS, Microsoft Azure or Google Compute engine) or on the containerized environments (such as Docker, Kubernetes, VMWare, Apache Mesos)
Apache Ignite vs Redis
| Redis | Apache Ignite |
|---|---|
| Used to improve application performance by using in-memory key-value pairs. | Used more than a cache. It can slide in between application and data-layers without having to rewrite any code. |
| Relational data needs to be mapped to another model. | Replaces ODBC/JDBC drivers with Apache driver and can be used as an interface with SQL to support ACID transactions. |
| Used as a key-value store for application data. | Used more than a key-value store to be used as an in-memory distributed SQL database. Persistent storage can be used to keep a subset of data in memory. Provides immediate availability on restart without having to wait for data to get loaded in memory first. |
| Implementation in C only. | Implementation in C++, Java and .Net. |
| Optimistic locking (check if the record was updated by someone else before you commit the transaction). | Both optimistic and pessimistic locking (take an exclusive lock so that no one else can start modifying the record). |
How Cazton Can Help You With Apache Ignite
We have experts who have used Redis in many multi-million dollar projects with data up to a petabyte scale. We have real world experience using this technology and leverage its overall capabilities in many different scenarios. We offer the following services at the Enterprise level, team level and/or the project level:
- Help you with Apache Ignite consulting, development and training services.
- Help you with Polyglot persistence strategy tailored to your needs.
- Help you with caching best practices.
- Help you with Apache Ignite best practices.
- Help you with Apache Ignite security implementation and support.
- And any other related services including (Big Data, Search, NoSQL and RDBMS)
At Cazton, our team of expert developers, consultants, architects, data analysts, data scientists, DBAs, awarded Microsoft Most Valuable Professionals and Google Developer Experts understand the changing requirements and demands of the industry. We help you make the right decision to achieve your business goals. We have the expertise to understand your requirements and tackle your data problems. Learn more about database, cloud, big data, artificial intelligence and other consulting and training services.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.