MongoDB Consulting
- Break free from legacy database constraints: Traditional databases slow down innovation, while MongoDB’s flexible data model gives your developers the freedom to build and iterate without structural limitations.
- Why leading enterprises trust our benchmarks: Our proprietary benchmarking framework, used by Fortune 500 companies, helps assess the real-world performance of MongoDB platforms including Azure Cosmos DB for MongoDB vCore and MongoDB Atlas. Read the full report.
- Scale smarter, perform faster: We fine-tune MongoDB for your real-world workloads, optimizing query speed, indexing, replication, and sharding so your applications run faster, scale seamlessly, and stay cost-efficient under pressure.
- Modernize your apps without downtime: We migrate your legacy systems to MongoDB with minimal risk, preserving operational continuity while upgrading your data capabilities.
- Build architecture that fits your business: Our MongoDB deployments integrate cleanly with your infrastructure while meeting your performance, security, and compliance needs.
- Industry-specific expertise that delivers results: We tailor MongoDB solutions to your industry’s compliance rules, data models, and operational needs that generic solutions miss.
- Top clients: We help Fortune 500, large, mid-size and startup companies with Big Data and AI development, deployment (MLOps), consulting, recruiting services and hands-on training services. Our clients include Microsoft, Google, Broadcom, Thomson Reuters, Bank of America, Macquarie, Dell and more.
Is your organization struggling to scale legacy databases, control rising maintenance costs, or adapt rigid schemas to changing needs? Are your developers spending more time managing database limitations than building new features? Are complex ETL pipelines and data silos slowing down your analytics and business insights? These challenges represent the breaking points that drive many enterprises to consider MongoDB as a strategic database platform, but successful implementation requires more than just installing new software.
MongoDB adoption represents a fundamental shift in data architecture philosophy, requiring organizations to rethink established patterns for data modeling, access patterns, and application design. This document-based database offers tremendous flexibility but demands careful consideration of how data will be queried, updated, and scaled as applications evolve. Without proper planning, organizations risk creating systems that fail to leverage MongoDB's strengths or, worse, introduce new performance and reliability issues that undermine business operations.
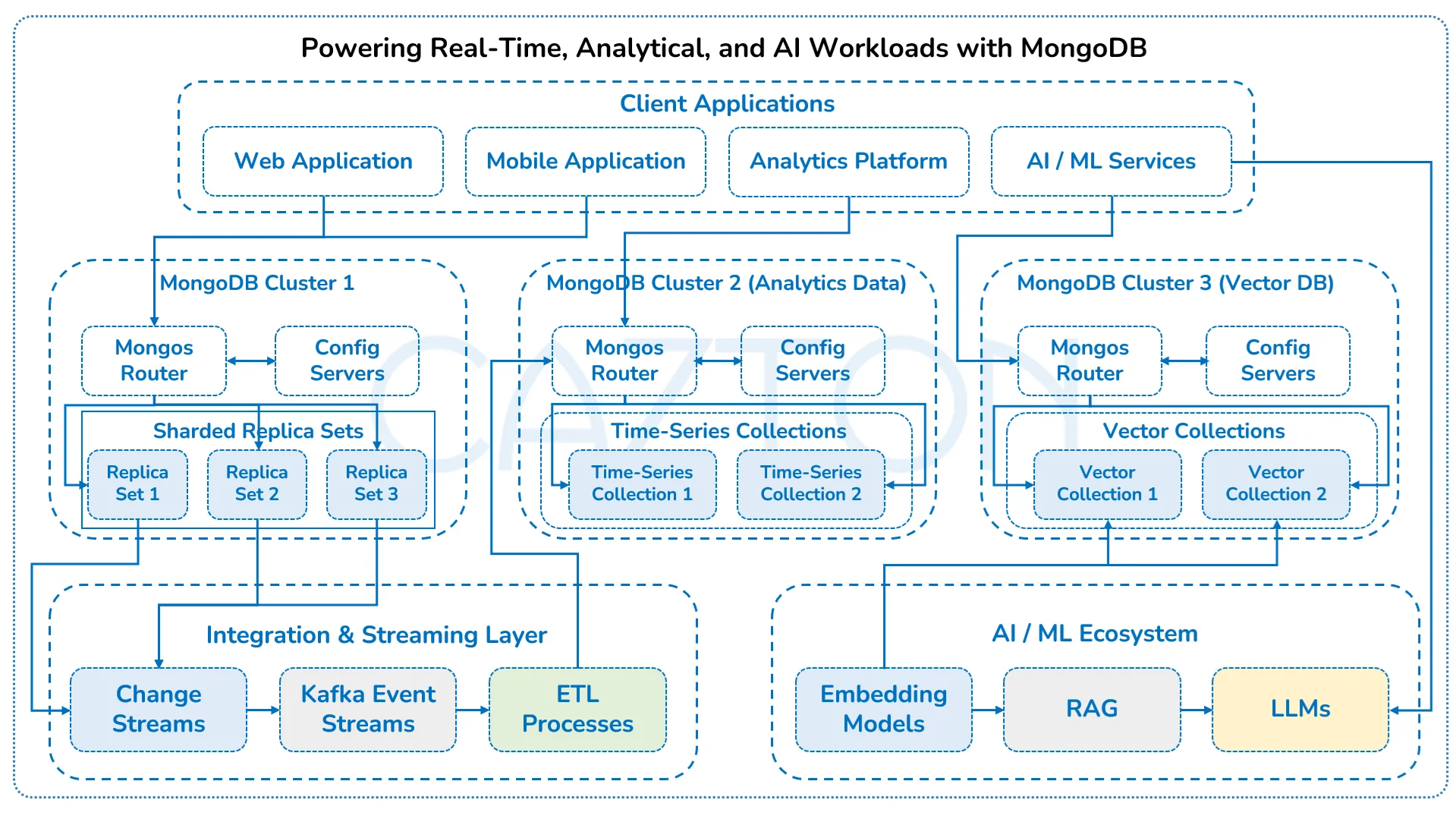
The transition to MongoDB involves complex decisions around data migration strategies, schema design, indexing approaches, and deployment architectures that must align with specific business requirements. Organizations must navigate questions of data consistency models, sharding strategies, and backup methodologies while ensuring their teams develop the skills needed to operate in this new paradigm. We partner with your leadership team to turn MongoDB into a strategic enabler for the business. With a strong focus on architecture, scalability, and governance, we ensure your implementation supports your broader transformation goals, not just technical milestones.
The Database Revolution Your CTO Needs to Understand
MongoDB's rapid growth to $2.1 billion(1) in revenue reflects a fundamental shift in how enterprises approach data management, yet many organizations hesitate to make the transition. The primary concern isn't MongoDB's technical capabilities but rather the complexity of enterprise implementation without proper strategic guidance.
Your industry peers are grappling with similar challenges: legacy systems that can't adapt to changing business requirements, development teams constrained by rigid database schemas, and IT infrastructure that struggles to scale with business growth. These limitations create competitive disadvantages that compound over time, making digital transformation initiatives more expensive and time-consuming.
MongoDB's flexible document model addresses these pain points directly, but successful implementation requires more than technical deployment. It demands a purpose-built plan that considers your existing infrastructure, compliance requirements, and long-term business objectives. Organizations that attempt self-implementation often encounter scaling issues, security vulnerabilities, and performance bottlenecks that could have been avoided with proper planning and expertise.
Our team of experts can help you implement MongoDB in the right way. We've guided numerous enterprises through MongoDB implementations, helping them avoid common pitfalls while maximizing the technology's business impact. Our approach ensures your MongoDB deployment becomes a strategic asset rather than just another technology project.
What You Need to Know About MongoDB
MongoDB stores data in documents rather than tables, fundamentally changing how your applications interact with information. Think of it as the difference between filing documents in rigid filing cabinets versus flexible folders that can hold any type of content. This flexibility means your development teams can build applications faster, adapt to changing requirements more easily, and integrate diverse data sources without complex transformations.
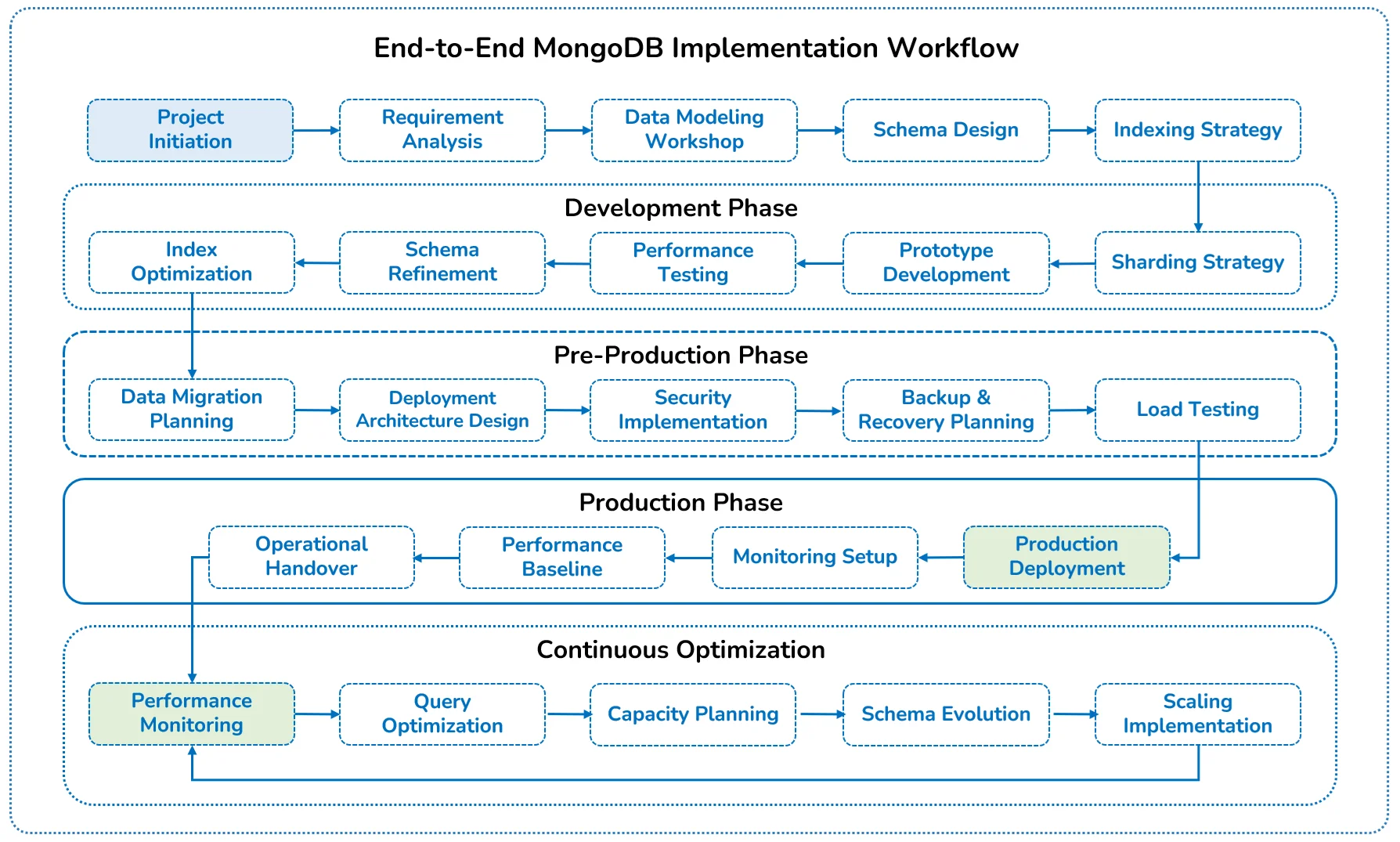
At its core, MongoDB operates as a distributed database system designed for horizontal scalability, high availability, and performance at scale. The database architecture consists of multiple layers working in concert:
- A storage engine responsible for persisting data to disk and managing memory.
- A query engine that processes and optimizes database operations.
- A replication system that ensures data redundancy and availability; and
- The sharding framework that distributes data across multiple servers.
This layered architecture allows enterprises to customize MongoDB deployments to their specific requirements, selecting appropriate storage engines based on workload characteristics, configuring replication topologies to meet availability needs, and implementing sharding strategies that align with data access patterns.
Its architecture supports deployments ranging from single-server development environments to massive, distributed clusters spanning multiple global data centers, all while maintaining a consistent programming model.
MongoDB has evolved from a simple document store to a comprehensive data platform ecosystem that addresses enterprise requirements for security, management, and integration. The database incorporates sophisticated security features including role-based access control, field-level encryption, and auditing capabilities that satisfy regulatory compliance requirements in highly regulated industries.
We help your teams turn MongoDB’s architectural strengths into real business results. From identifying the right deployment model to aligning your data flows with performance goals, we tailor every implementation to your enterprise needs. Whether you're consolidating siloed data, scaling globally, or modernizing legacy systems, we ensure MongoDB becomes a dependable engine for growth, not just another tool in your stack.
Build Faster and Smarter with MongoDB
- Flexible data model for dynamic applications: MongoDB’s document-oriented, schema-less structure lets you map business logic directly in the data layer. Our clients routinely accelerate launches by weeks or months, sidestepping lengthy relational data model iterations. New attributes, nested objects, and rich relationships are added in hours, not sprints, allowing continuous business adaptation.
- Horizontal sharding and scale-out consistency: Built-in sharding distributes data across multiple nodes, optimizing for performance, cost and resilience. We architect globally distributed clusters with adjustable consistency and write tolerance, supporting compliance needs, low-latency user experiences, and uninterrupted operations, even during hardware failures or regional outages.
- Multi-model access and analytics in one platform: Documents, time-series, graph, geospatial, and text-search workloads all run on a single MongoDB cluster. We enable integrated analytics, full-text search, and event streams so that product teams, analysts, and AI/ML solutions use the same data source, eliminating ETL overhead and driving deeper insights at lower cost.
- Built-in high availability and disaster recovery: MongoDB’s replica sets automate failover, backup, and recovery across zones, clouds, and regions. Our runbooks and cloud automation ensure instant failover, minimal data loss, and consistent business continuity. Data is protected through encryption, role-based controls, and audit trails tailored for any regulatory or geographic requirements.
- Integrated security and compliance controls: We build advanced policies for encryption, audit logging, IP whitelisting, field-level redaction, and always-on monitoring. We align every security layer, network, application, platform, to ensure zero compromise on data privacy, separation of duties, and regulatory compliance.
- Seamless migration and cloud-native deployment: MongoDB integrates natively with Kubernetes, Terraform, Docker, and CI/CD. We design zero-downtime migrations and hybrid, multi-cloud strategies that minimize disruption, streamlining rollout for both new apps and legacy modernization. Our playbooks prevent data loss, automate schema conversion, and enable phased cutover at enterprise scale.
- Full JavaScript and API-driven development: Our clients benefit from unified JavaScript development with Node.js, React.js, and GraphQL, leveraging MongoDB’s dynamic JSON model. This accelerates developer productivity, eliminates impedance mismatches, and enables composable, API-first transformations across web, mobile, and services.
- Observability and intelligent automation: MongoDB provides native integration with monitoring, alerting, and self-healing operations tools. Our experts implement custom dashboards and AI-driven anomaly detection, anchoring 24/7 reliability, cost control, and rapid root-cause response for mission-critical workloads.
- Rapid prototyping and iterative business delivery: With its flexible schema and robust drivers, MongoDB enables developers to create pilot systems in days, scale rapidly, and continuously iterate with minimal refactoring. Our expert's partner with clients to launch MVPs quickly, gather live feedback, and scale production features only when business validation is certain.
- Multi-region, cross-cloud deployment and analytics: We architect MongoDB clusters for global distribution, across AWS, Azure, GCP, and private data centers, powering data residency, latency-sensitive experiences, and regulatory coverage. We ensure analytics workloads are collocated with operational data for immediate, global business intelligence.
An Ecosystem That Empowers Your Team
MongoDB’s open-world ecosystem is a force multiplier for enterprise modernization. We design technology stacks leveraging best-in-class integrations across categories, ensuring every workload is robust, extensible, and future-ready.
- API and web frameworks: Express.js, Fastify, and Hapi connect Node.js services and serverless backends to MongoDB with simple, high-performance APIs. NestJS adds dependency management and architecture enforcement in large systems, while Mongoose provides robust schema modeling for developer productivity and data validation. We help teams choose, scaffold, and standardize frameworks for both greenfield and brownfield projects, accelerating both build and maintenance.
- Real-time and streaming data: With native support for change streams, MongoDB enables real-time reactions to inserts, updates, and deletes in business-critical apps. Kafka, RabbitMQ, and AWS Kinesis integration unlocks full event-driven, reactive architectures. We architect pipelines with socket frameworks (Socket.io, SignalR) and streaming APIs, connecting dashboards, IoT, and user services directly to live operational data.
- Full-stack and SaaS enablement: Next.js and Nuxt.js, paired with GraphQL (Apollo, Hasura), combine server-side rendering, multi-region CDN caching, and instantaneous content updates for global SaaS. We build full-stack/multi-tenant platforms connecting mobile, browser, and back-office tools to a single MongoDB core, reducing ops friction and keeping pace with market demand.
- Testing and data quality automation: Mocha, Chai, Jest, and Cypress provide unit, integration, and end-to-end test coverage for MongoDB-backed applications. We implement CI/CD policies including seeded test data, schema diff checks, and environment-specific validation, reducing deployment risk and improving long-term trust in data operations.
- DevOps pipelines and deployment: MongoDB Atlas, Docker, Helm, and Terraform enable fast deployment, replica scaling, secrets management, and policy enforcement. Our DevOps solutions support blue/green, rolling, and canary deployments with live data validation and failback support. We provide migration playbooks, cloud automation, IAM/SSO, and site reliability runbooks.
- Observability, APM, and monitoring: Datadog, New Relic, Prometheus, Elastic Cloud, and Atlas’s own Ops Manager offer full-stack metrics, query profiling, threshold alerting, and anomaly detection tuned for dynamic MongoDB environments. We centralize metrics and build escalation protocols to ensure that every production workload is visible, actionable, and meets business SLAs.
Why Your AI Needs a Hybrid Approach
Modern AI applications rely on more than structured data; they require the ability to store and search for high-dimensional vectors that represent semantic meaning. MongoDB, through capabilities like Atlas Vector Search and the Azure Cosmos DB for MongoDB (vCore) offering, supports this natively. These solutions allow your systems to retrieve information based on context and similarity, rather than exact keyword matches, enabling more intelligent search, recommendations, and conversational interfaces across a wide range of use cases.
Semantic search in MongoDB uses vector embeddings generated by machine learning models to determine relevance based on meaning. These embeddings can be stored directly alongside your operational data, enabling proven approaches like RAG, RAFT, personalized customer experiences, and real-time AI workflows, all while maintaining a unified, document-based model. Whether deployed on AWS, Azure, or GCP, these capabilities can be integrated into existing architectures and scaled as needed, without introducing unnecessary complexity.
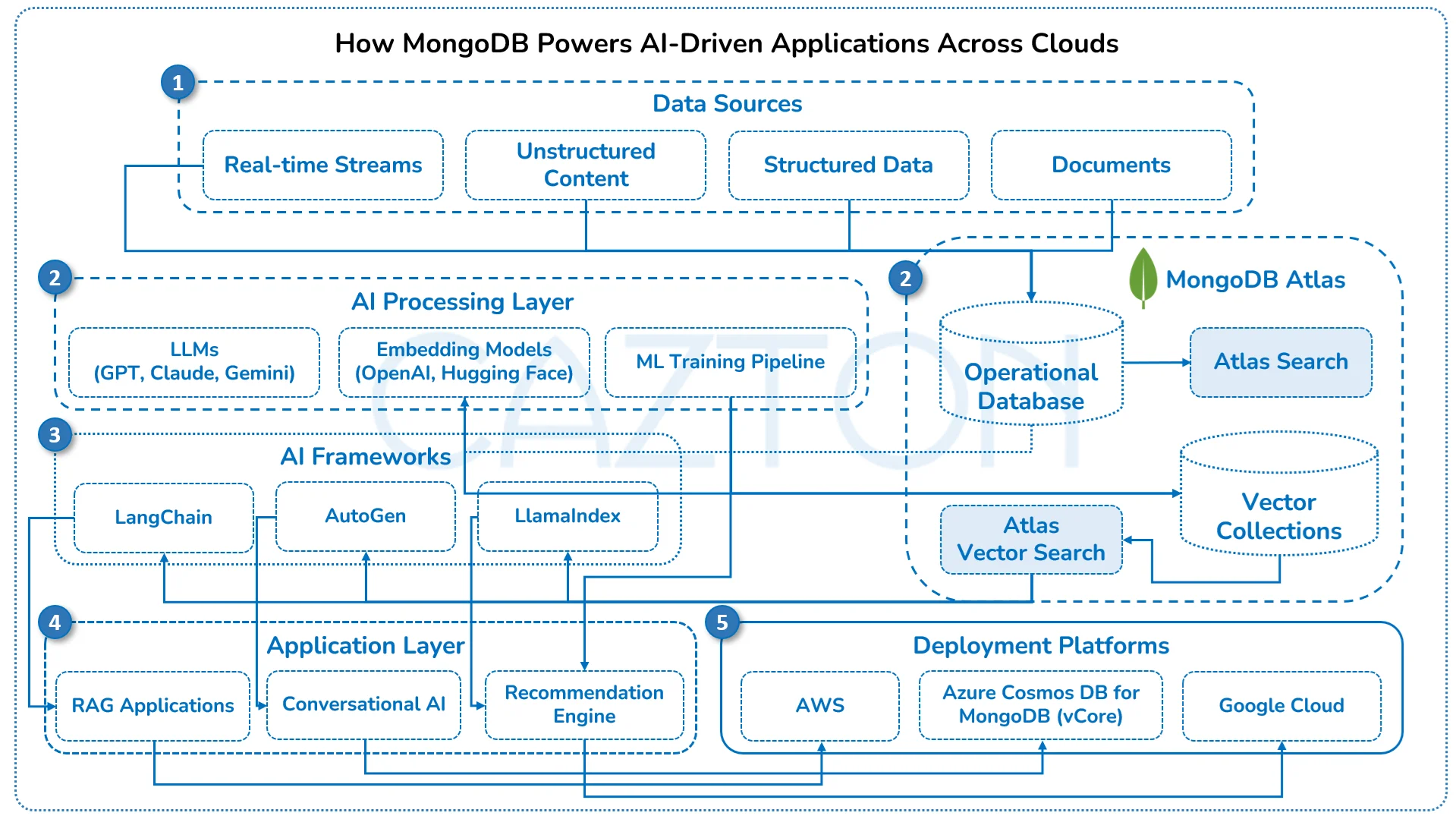
AI agents and intelligent workflows benefit from the ability to access both structured records and semantically rich content in one place. Vector similarity queries help applications match intent, behavior, and content in ways that traditional databases cannot. This is particularly valuable in domains such as customer service, product discovery, and knowledge management, where the goal is to provide relevant responses, not just literal ones.
Our team works closely with organizations to implement these capabilities in a secure, performant, and scalable way. From designing vector indexing strategies to embedding generation (via OpenAI) to integrating with AI frameworks like LangChain, Semantic Kernel, LlamaIndex, or AutoGen, we ensure your solution meets the demands of production-scale AI while aligning with your broader data strategy. Whether you're building new AI applications or enhancing existing ones, we help integrate your operational systems with AI-powered experiences.
Why Your Analytics Strategy Needs Flexibility
Modern analytics require architectures that can handle high volumes of structured and unstructured data from diverse sources. Document databases like MongoDB offer a flexible model suited for real-time, heterogeneous data, making it easier to ingest everything from transactional records to sensor streams and social content without rigid schemas or complex ETL processes.
Organizations often need to balance the performance of data warehouses with the scale and variety supported by data lakes. Solutions like Microsoft Fabric and Databricks enable this convergence, while MongoDB’s compatibility with big data tools like Apache Spark, Hadoop and Kafka allows your operational data to be fed directly into analytical platforms. We help design these integrations, ensuring your data flows support both real-time decisions and long-term insights.
Our role is to architect reliable data pipelines, align operational databases with enterprise analytics platforms, and ensure consistency, governance, and scalability. Whether you're modernizing legacy systems or enabling real-time analytics, we bring the experience needed to build a unified and efficient data architecture.
Why Most MongoDB Implementations Fail
Despite its engineering strengths, MongoDB transformation projects frequently stall or fail to achieve target business outcomes. Our audit and remediation practice has uncovered consistent root patterns. Understanding and proactively correcting these missteps is crucial for delivering sustainable ROI and minimizing rework or business disruption.
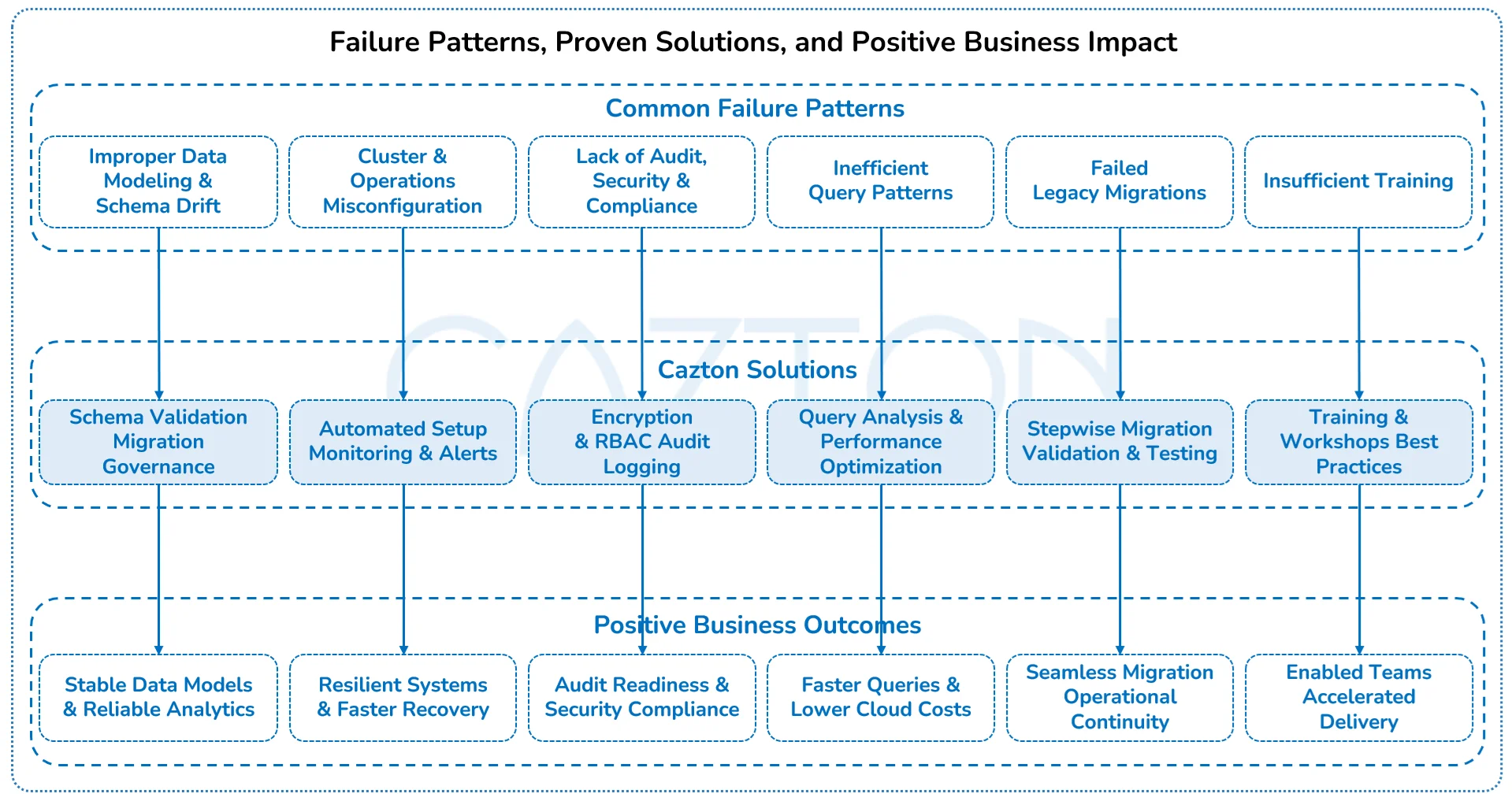
- Improper data modeling and schema drift: Teams new to MongoDB often underappreciate the impact of data shape changes, inconsistent document structure, or suboptimal index strategies. Absent strong schema governance, applications encounter difficult bugs, performance cliffs, and unpredictable queries at scale. We deploy schema validation, versioned migration, and intensive modeling sprints, closing these gaps before they become costly fires.
- Cluster and operations misconfiguration: MongoDB’s flexibility can become a risk when replication, sharding, backup, and failover are left to default settings. This can lead to hidden single points of failure, missed backups, and slow disaster recovery. We apply proven configuration practices, automate setup, and implement monitoring to ensure resilience and recovery are built in from day one.
- Lack of audit, security, and compliance controls: Without field-level security and regulatory-mandated controls, unauthorized data access or breach risks are amplified. We enforce encryption, audit logging, granular RBAC, and strong secrets management from dev to prod, building trust, privacy, and audit readiness into every project.
- Inefficient query patterns and resource hot spots: Unoptimized queries, non-indexed reads, and over-frequent scans create undiagnosed bottlenecks and lead to inflated cloud costs. Our query analysis, performance audits, and dynamic profiling surface and resolve these bottlenecks, restoring efficiency while providing actionable metrics for leaders.
- Failed or manual migrations from legacy systems: Many enterprises fail to move beyond pilots due to poorly mapped data flows, brittle ETL, or an undefined migration process. The business impact is a continuing reliance on legacy lock-in and mounting technical debt. We lead migrations with stepwise tests, validation, and staged cutovers, ensuring no data or business process is left behind.
- Insufficient training and cultural enablement: MongoDB’s leap from SQL to document-first requires deliberate skills transfer and collaboration. Our experts drive education, documentation, and cross-function workshops, empowering teams to maximize MongoDB’s strengths beyond just “using the API.”
Our methodology overcomes these risk factors by embedding governance, best practices, code reviews, and automation from project inception to post-launch optimization. Comprehensive assessment, phased adoption, and our ongoing partnership mean issues are anticipated and solved before they can impact production or user experience.
Case Studies
Energy: Smart Grid Operations and Predictive Maintenance
- Challenge: A national energy provider struggled with their legacy relational database architecture that couldn't handle the massive influx of real-time grid telemetry data with varying schemas. Their rigid table structures required constant schema migrations as new sensor types were deployed, causing downtime during critical operations. Complex joins across normalized tables created performance bottlenecks when correlating time-series data from thousands of grid assets, making real-time anomaly detection nearly impossible.
- Solution: We migrated their infrastructure to a document-based architecture that naturally accommodated the diverse data structures from different sensor manufacturers without schema modifications. Time-series collections enabled efficient storage and querying of massive telemetry datasets, while flexible document modeling allowed seamless integration of maintenance logs, asset specifications, and operational data. Horizontal scaling capabilities handled peak loads during grid stress events, and built-in replication ensured high availability across geographically distributed data centers.
- Business impact: Operations teams gained real-time visibility into grid performance with sub-second query responses, predictive maintenance algorithms processed historical patterns more efficiently, and system reliability improved dramatically. The flexible schema eliminated development bottlenecks when integrating new equipment types, while automated failover capabilities ensured continuous monitoring during critical infrastructure events.
- Tech stack: MongoDB Atlas, Apache Kafka, Express.js, Angular, Java, Python, Azure, Tableau, Airflow, Apache Superset, dbt, Azure Event Hubs.
Education: Adaptive Learning and Assessment Platform
- Challenge: An EdTech company faced severe limitations with their relational database system that couldn't efficiently store the diverse data types required for personalized learning. Student interaction logs, assessment results, content metadata, and behavioral patterns each required different table structures, leading to complex joins that degraded performance as user bases grew. The rigid schema made it difficult to add new assessment types or learning analytics features without extensive database restructuring and downtime.
- Solution: We implemented a document-centric data architecture that unified student profiles, learning content, and behavioral analytics in flexible collections. Dynamic schema capabilities allowed rapid deployment of new assessment formats and learning modules without database migrations. Rich querying capabilities enabled real-time personalization algorithms to process student data efficiently, while built-in indexing strategies optimized performance for both transactional operations and analytical workloads across millions of student interactions.
- Business impact: Platform response times improved significantly for personalized content delivery, educators could deploy new learning features without technical delays, and student engagement increased through more responsive adaptive assessments. Development cycles accelerated as teams could iterate on data models without complex migration processes, while horizontal scaling supported rapid user growth across multiple geographic regions.
- Tech stack: MongoDB, Next.js, Redis, .NET, Azure Functions, Scikit-learn, Cloudflare Workers, TypeScript, LightGBM, Pinecone, OpenAPI.
Agriculture: Precision Farming and Remote Field Analysis
- Challenge: A smart agriculture firm encountered major limitations with their relational database system that couldn't efficiently handle the variety and volume of agricultural data. Environmental sensors, drone imagery metadata, equipment telemetry, and field observations each required different table structures, making it difficult to correlate data across time and location. The rigid schema couldn't accommodate the seasonal variations in data collection patterns, and complex joins severely impacted performance when analyzing large geographic datasets for crop modeling and yield prediction.
- Solution: We transitioned to a document-based architecture that naturally accommodated diverse agricultural data types within unified collections. Geospatial indexing capabilities enabled efficient location-based queries across vast farmlands, while time-series collections optimized storage and retrieval of sensor data spanning multiple growing seasons. Flexible document structures allowed seamless integration of varying equipment specifications and observational data formats without requiring schema changes or system downtime.
- Business impact: Research teams gained faster access to comprehensive field data for model training, farmers received real-time insights through improved query performance, and decision-making shifted from reactive to predictive across the entire agricultural cycle. The flexible architecture eliminated development bottlenecks when integrating new sensor technologies, while horizontal scaling supported expansion across multiple geographic regions and farming operations.
- Tech stack: MongoDB, TimescaleDB, React.js, Node.js, HL7 FHIR, AWS Lambda, Grafana, Go, Prometheus, Apache Flink, Hugging Face Transformers.
Hospitality: Centralized Guest Experience and Loyalty Intelligence
- Challenge: A global hospitality group struggled with fragmented guest data spread across multiple relational databases that couldn't efficiently unify diverse data types. Guest preferences, booking history, loyalty interactions, and service requests each resided in separate normalized tables, requiring complex joins that degraded performance during peak booking periods. The rigid schema structure made it difficult to accommodate varying property types and regional service offerings, while maintaining data consistency across multiple brands and geographic locations proved challenging with traditional replication methods.
- Solution: We implemented a unified document architecture that consolidated guest profiles, booking patterns, and interaction history into comprehensive collections. Flexible schema design accommodated diverse property types and regional variations without requiring database restructuring. Advanced querying capabilities enabled real-time personalization across touchpoints, while built-in replication features ensured consistent guest experiences across global properties. Document-based storage naturally supported the hierarchical relationships between brands, properties, and guest interactions.
- Business impact: Guest personalization improved through faster data access across all touchpoints, marketing teams executed more targeted campaigns with unified customer views, and operational efficiency increased through streamlined data management. The flexible architecture eliminated integration delays when adding new properties or service types, while global replication capabilities ensured consistent guest experiences regardless of location or booking channel.
- Tech stack: MongoDB Atlas, Atlas Data Lake, FastAPI, Java, ElasticSearch, Google Cloud Run, React.js, GCP, BigQuery, dbt Cloud, OpenSearch.
Manufacturing: Industrial Automation and Shop Floor Intelligence
- Challenge: A global manufacturer faced significant database limitations with their legacy relational system that couldn't efficiently handle the diverse data streams from connected factory equipment. Machine telemetry, operator logs, quality inspections, and maintenance records each required different table structures, creating performance bottlenecks when correlating data for real-time production insights. The rigid schema struggled to accommodate new equipment types and sensor configurations, requiring complex migrations that disrupted production monitoring systems.
- Solution: We developed a document-based operational data platform that unified machine telemetry, production logs, and quality data into flexible collections. Time-series optimizations enabled efficient storage and querying of high-frequency sensor data, while dynamic schema capabilities allowed seamless integration of new equipment types without system modifications. Advanced indexing strategies supported both real-time monitoring queries and complex analytical workloads across multiple production facilities.
- Business impact: Production teams achieved real-time visibility into shop floor operations with improved query performance, quality control processes became more proactive through faster anomaly detection, and manufacturing efficiency increased across all facilities. The flexible architecture eliminated integration delays when deploying new equipment, while horizontal scaling supported expansion to additional manufacturing sites without performance degradation.
- Tech stack: MongoDB, AWS IoT, React Native, Redshift, Datadog, Node-RED, Rust, Amazon SageMaker, Mapbox, Apache NiFi.
How Cazton Can Help You With MongoDB
We have deep experience in MongoDB modernization, helping organizations design, migrate, and scale data environments to meet evolving business needs. We do not just advise; we build, migrate, optimize, and support mission-critical data environments across all major cloud platforms. Our consulting engagements begin by thoroughly assessing your business goals, risk profile, current architecture, and key use cases. With this foundation, our cross-functional team designs a practical, phased roadmap that translates potential into measurable business outcomes.
We lead with modernization assessments, blueprinting, hands-on delivery, continuous enablement, and operational runbooks. Along the way, we invest in skills transfer, automation, and measurable KPIs so that your internal teams are equipped to manage and extend new platforms well beyond go-live and product launch. Our multi-cloud delivery, training, and support reach organizations in financial services, healthcare, retail, SaaS, public sector, and more wherever digital transformation accelerates value.
- Horizontal scalability and growth planning: We design MongoDB architectures that scale effortlessly across regions, workloads, and business units, supporting everything from bursty user traffic to petabyte-scale data while maintaining high performance and availability.
- Workload-aware performance tuning: We optimize MongoDB for your specific query patterns, indexing strategies, and operational workloads, ensuring low-latency performance even under high concurrency and massive data volumes.
- Comprehensive lifecycle development: From first vision to long-term transformation, we architect, build, and optimize MongoDB applications and platforms. Our well-defined processes ensure technical, organizational, and regulatory alignment at every stage.
- Cloud-native and hybrid cluster design: Our expertise in on-prem, MongoDB Atlas, and hybrid deployments ensures seamless performance, high availability, data residency, and regulatory compliance.
- Legacy migration and phased cutover: We modernize and migrate you away from costly, inflexible relational or batch ETL systems to efficient, future-ready MongoDB platforms; using stepwise staging, dual writes, schema migration, validation, and rollback plans to eliminate data loss risk.
- API, IoT, big data, and analytical ecosystem integration: We connect MongoDB with your operational APIs, microservices, AI/ML pipelines, and event-driven architectures to drive value from every new and legacy data source in your business.
- Performance optimization and cost management: Rigorous profiling, configuration, and index tuning eliminate cost overruns and performance lags. Our monitoring frameworks give leaders confidence in 24/7 stability.
- Security, governance, and compliance: We deliver comprehensive strategies and automation for encryption, auditing, access controls, and regulatory mapping, future-proofing your organization against evolving legal and industry requirements.
- DevOps automation, CI/CD, and infrastructure as code: We implement containerized workloads, deployment pipelines, and policy guardrails, accelerating go-live and audit, and supporting agility at every business turn.
- Change management, enablement, and SRE/SME support: We don’t just deliver systems, we train your teams, create documentation, upskill operators, and establish site reliability protocols for sustainable, long-term success.
- Data observability and advanced monitoring: We integrate enterprise tools (Datadog, New Relic, Atlas, Elastic) for real-time visibility, anomaly detection, and cost forecasting across hybrid and multi-cloud workloads.
- AI/ML integration strategies: Our teams build the pipelines and APIs needed for your data science teams to unlock MongoDB’s value for predictive analytics, personalization, and process automation at scale.
- Serverless, edge, and event-driven platform design: With experience on AWS Lambda, Azure Functions, CDN edge, and streaming platforms, we architect deployment strategies for hyper-scale and low-latency next-gen workloads.
- Testing, QA, and release automation: We build rigorous, automated test and staging programs, environment parity, and 24/7 on-call coverage, so every critical data service delivers reliable outcomes to the business.
- Innovation strategy, technical workshops, and executive advisory: We partner with business stakeholders to define and execute on long-term data and digital innovation goals, develop capability assessments and models, and maintain an ever-evolving tech radar for competitive positioning.
Our excellence is not just in code, but in measurable outcomes, leadership partnerships, and operational transformation based on real-world standards and experience. Contact us today to begin your MongoDB journey, from assessment and architecture to global, secure, and scalable delivery. Accelerate your business performance and resilience with the world’s most advanced MongoDB services partner.
References:
(1) Source: Yahoo finance. Date: 01/31/2025
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.