An elite AI consulting firm delivering high-impact, enterprise-grade solutions including custom-built AI chatbots and advanced automation systems tailored to complex business needs.
Cazton offers a comprehensive suite of services encompassing custom software development, consulting, recruiting, and training in cutting-edge technologies. We specialize in Artificial Intelligence, Natural Language Processing (NLP), Machine Learning (ML), Deep Learning, Chatbots, Computer Vision, Speech Recognition, Recommender Systems, Predictive Analytics, Image and Video Analysis, Virtual Assistants, Data Science, Pattern Recognition, Generative Adversarial Networks (GANs), Expert Systems, Reinforcement Learning, Cognitive Computing, Sentiment Analysis, Fraud Detection, Health Informatics, Decision Support Systems, and much more.
Our accomplished team comprises experienced professionals, including NLP Engineers, Machine Learning Engineers, Deep Learning Specialists, Chatbot Developers, Data Scientists, Research Scientists, R&D Engineers, Distributed Systems Engineers, Virtual Assistant Developers, Business Intelligence Developers, Computer Vision Engineers, and AI Experts. We are dedicated to delivering services that are not only high-quality but also cost-effective.
GEO Consulting
Cazton specializes in Generative-Engine Optimization (GEO) - the strategic practice of optimizing your digital content to maximize visibility and authority in AI-generated responses from systems like ChatGPT, Claude, and Gemini.
As customer discovery...
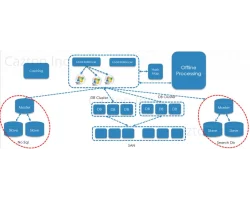
AI Agents for SAP
Transforming Enterprise Operations Through Intelligent SAP Automation
Your SAP systems power critical business operations, but manual processes still consume valuable time and resources that could be focused on strategic growth initiatives. While you...
Google AI Consulting
The technologies showcased at Google I/O 2025 represent a major milestone for enterprise AI adoption, introducing capabilities that move far beyond simple chatbots and basic process automation. However, the disconnect between technological possibilit...
OpenClaw Consulting
OpenClaw is one of the most talked-about open source AI agent frameworks, but deploying it in an enterprise environment requires architecture, security, and governance work the core project does not provide. This article walks through the evaluation ...
Vibe Coding Support
Vibe coding - building software by describing what you want in plain English and letting AI generate the code - went from a catchy phrase to an industry-wide movement in under a year. The productivity gains are real, but so are the risks: security vu...
Cazton Whiz
Run your entire job from your phone.
Cazton Whiz
Cazton Whiz is a private, local-first tool that turns your phone into a command center for serious work - not a remote desktop viewer, but a way to direct real computation on your own machine from anywhere. This article covers how it works, real-worl...
AI Employees for Your Business
AI Employees for Your Business
Every business function generates work that is repetitive, judgment-light, and expensive to staff around the clock. AI employees change that equation. They operate inside your existing workflows, handle the high-volume first pass across customer serv...
AI Employees for Sales
AI employees qualify leads, personalize outreach, and surface the right offer at the right moment. Your sales team focuses on closing while AI handles the volume work at a scale no human team can match.
AI Employees for Finance
AI employees close books faster, flag anomalies before they compound, automate reconciliation, and surface insights that let your finance team focus on strategy rather than data entry.
AI Employees for IT Support
AI Employees for IT Support
AI employees resolve tickets proactively, monitor system health, automate routine maintenance, and escalate only when human intervention is required, keeping infrastructure running without manual round the clock oversight.
AI Agent Traps
AI agents that can browse, retrieve, remember, and act introduce an attack surface that extends far beyond the system prompt. This brief maps the six categories of environmental manipulation that autonomous agents face - content injection, semantic m...
AI Consulting
AI Solutions That Simply Work
AI Consulting
Five years from now, when you look back, imagine feeling proud that you embraced AI as a transformative force. It could be the decision that elevated your career, accelerated your personal growth, and unlocked new levels of success for your company. ...
AI Marketing
Cazton AI Marketing keeps your brand active and visible by automatically creating and publishing content across Instagram, LinkedIn, Facebook, X and more. You focus on growing your business while we handle the rest.
Azure AI Consulting
Are you watching competitors gain market advantage through AI while your organization struggles to move beyond pilot projects? What if your AI initiatives could deliver the same measurable results as your most successful digital transformation projec...
Create Your AI Team
Stay Ahead of the Competition
AI Agents
The realm of artificial intelligence has birthed a transformative evolution: autonomous agents powered by Large Language Models (LLMs). These agents transcend mere text generation, becoming problem-solving entities. From intricate planning strategies...
Copilot Consulting
Every executive today faces the same critical question: How do you harness Microsoft Copilot to deliver real business value without getting lost in complexity? While competitors debate whether AI is revolutionary or just another tech fad, the smartes...
Evals Consulting
Are you confident your AI initiatives are delivering the ROI your board expects? Can you demonstrate to stakeholders that your AI investments are creating measurable business value? Most executives struggle to answer these questions with certainty. W...
MCP Consulting
Model Context Protocol (MCP) represents a fundamental shift in enterprise AI architecture - one that directly addresses your most pressing operational challenges while positioning your organization for sustained competitive advantage. Forward-thinkin...
OpenAI Agents API
Discover how OpenAI's latest Agents API is transforming AI development with autonomous agents, multi-turn conversations, and built-in tools like Web Search, File Search, and Computer Use. Learn how Cazton helps businesses integrate OpenAI, Azure Open...
Voice AI
The Future is Speaking Today
Voice AI
Imagine a world where interacting with technology feels as natural as having a conversation. Voice AI is transforming how we shop, work, and live - eliminating clicks and complicated interfaces in favor of simple, intuitive voice commands. From effor...
Azure Cosmos DB
All you need to know
Azure Cosmos DB Consulting
The evolution of database technologies has been exceptional. Right from the first pre-stage flat-file systems to relational and object-relational databases to NoSQL databases, database technology has gone through several generations and its history h...
.NET 8
Inside Scoop from Microsoft RD and MVP
.NET 8 Consulting
The software development realm is continuously evolving, and the advent of .NET 8, the latest long-term support (LTS) version, marks a significant milestone in this journey. Packed with a myriad of enhancements, optimizations, and fresh capabilities,...
UX Consulting
Have you ever launched a new feature or product that technically checked all the boxes - but still left users confused, frustrated, or disengaged? Maybe your onboarding flow felt clean on paper, but users dropped off before even hitting the “Get Star...