Databricks Consulting
- AI keynotes: Our CEO, Chander Dhall, successfully delivered keynotes for Global AI in multiple continents (Europe, US and Latin American) in the fall of 2022. He shared how to create a fully-scalable architecture at an extremely low cost. The keynote also compared the top AI (machine learning) offerings from Azure, AWS and GCP.
- Data lakes and data warehouse: The Databricks Lakehouse Platform combines the best of both worlds. It delivers the reliability, strong governance and performance of data warehouses while keeping the openness, flexibility and machine learning support of data lakes.
- Simple, open and multi-cloud: It simplifies the modern data stack by unifying data engineering, analytics, BI, data science and machine learning. It's build on open source technologies and offers management, security and governance on multiple clouds.
- Big Data/AI ecosystem: Cazton has helped Fortune 500, large, mid-size, and startup businesses with their Big Data/AI ecosystem that includes PyTorch, TensorFlow, Keras, Scikit-learn, NumPy, SciPy, Matplotlib, pandas, AirFlow, Fast.AI, Apache Spark, Azure Cosmos DB, Hadoop, HDFS, Impala/Hive, Kafka, Sqoop, Scala, Zookeeper, Parquet, ELK Stack, Tableau, Power BI, QlikView, R, Apache Ignite, Apache Beam, Flink and more.
On Aug 5, 2022, the CEO of Databricks announced Friday that his company has surpassed $1 billion in annualized revenue. This is more than double the $350 million in annualized revenue it reported just two years ago. This clearly rivals Snowflake's growth and paves way for Databricks' much-anticipated IPO in the near future.
Data is more expensive than oil. However, while data is an asset, lack of a unified data strategy can be a bottleneck, a huge cost to business and can lead to competitive disadvantages. According to some estimates in 2022, we generate a total of 2.5 quintillion bytes (2.5 e+9 GB) of data every single day. Most companies, especially large and mid-size companies have data silos that separate data engineering, analytics, BI, data science, and machine learning. The data strategy can be quite complex. It's common to see multiple data sources and duplication of data, not just in the same data store but also in multiple data sources within the same organization. Imagine a Fortune 500 that has acquired companies with different technology stacks and polyglot persistence.
We live in a world in which we need real time actions, not just analysis. We need to be able to allow the AI based models to intelligently offer an experience that users are looking for in real time. In order for that to happen, traditional silos do not work. It's too slow and complex. Databricks Lakehouse Platform solves that problem.
What is a Data Warehouse?
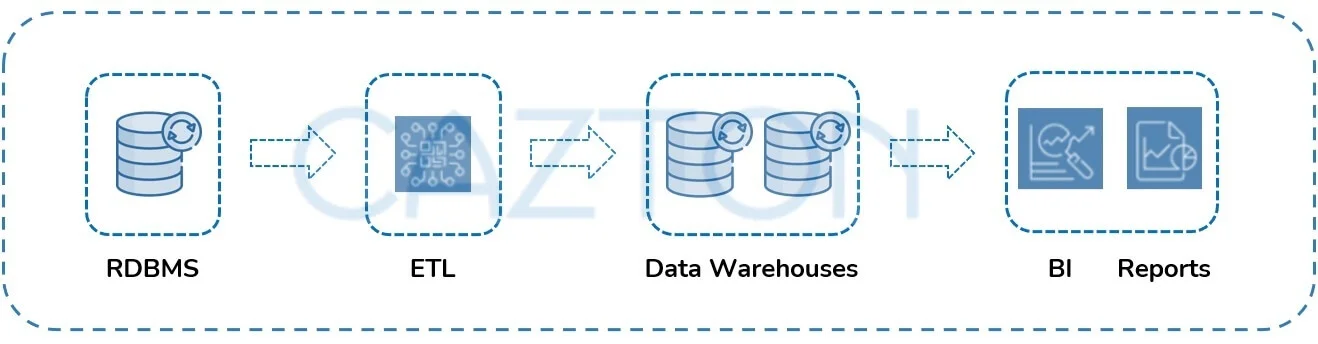
Before the advent of NoSQL databases, most data solutions were structured around RDBMSs (Relational Database Management System). They were great for structured data. Data warehouses used to import data from RDBMSs and were used to help in decision support and business intelligence applications. So, data warehouses were great for structured data. With the advent of phones, tables and IoT devices, modern enterprises must deal with enormous amounts of data: structured, semi-structured and unstructured. On top of that, they must deal with variable data, high velocity and volume. Data warehouses, even though adapted their architecture gradually, were not suited for such use cases. In some cases, they could be used to solve the problem, but at an elevated cost.
What is a Data Lake?
Given the limitations of data warehouses, architects envisioned a single data solution to gather company-wide data. Imagine a company with different workloads of data: structure, semi-structured and unstructured in different data sources. All that data would be now moved to a data lake, which is a single repository of data in multiple formats. However, some of the challenges were:
- Lack of enforcement of data quality standards.
- Lack of transaction support.
- Lack of unification of streaming, batching and traditional reads.
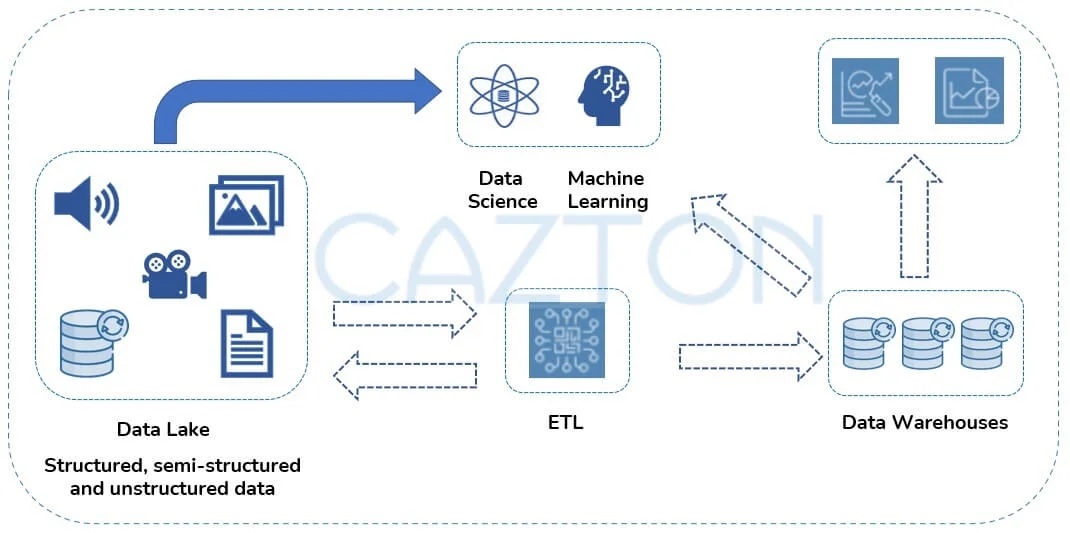
Artificial intelligence has made recent advances in processing unstructured data: audio, video, image and text. To solve this problem, gradually companies ended up with a bunch of systems: data warehouses, data lakes, and specialized systems (streaming, time-series, graph, and image databases). This makes the data strategy of a company highly inefficient, introduces delays, increases room for error and reduces competitiveness.
Databricks Data Lakehouse
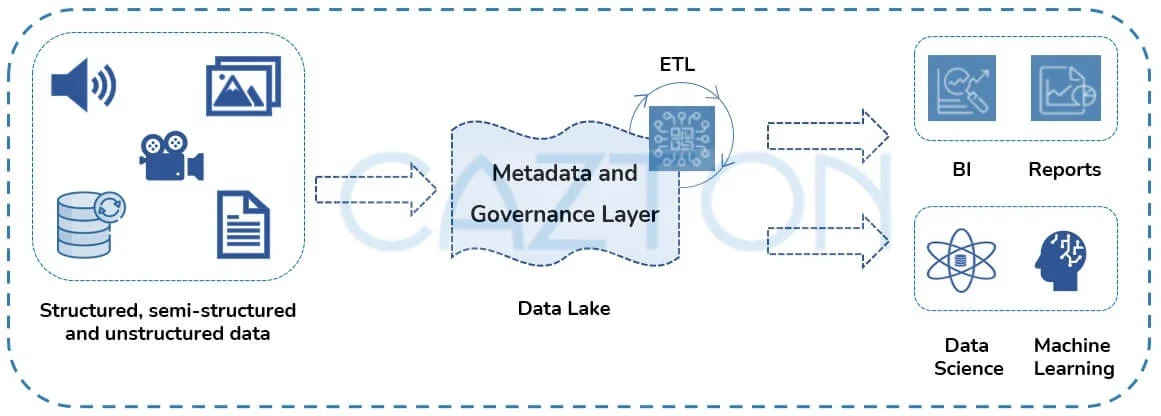
There has been an ever-increasing need for a flexible, high-performance data system that includes analytics, real-time monitoring, data science, and machine learning. The data lakehouse architecture was created after understanding the current and future needs of the enterprise. It's an attempt to address the limitations of data lakes. A data lakehouse is a new, open architecture that not just combines the best elements of data lakes and data warehouses but also addresses more use cases and fixes the underlying challenges. Data lakehouses redesigns data warehouses for the modern world. It uses similar data structures and data management features directly on top of low-cost cloud storage in open formats.
Key Features of Databricks Data Lakehouse
- ACID support: It's very common in the enterprise to have multiple APIs and applications constantly reading and writing data. Multiple parties can concurrently modify the same set of data. In order to ensure consistency, transaction support is essential. Data lakehouse guarantees ACID (Atomicity, Consistency, Identity, and Durability) transactions.
- Snowflake/star schema support: It supports enforcement of schema and its evolution. This involves supporting star or snowflake schema architectures. The Delta Lake transaction log serves as the single source of truth. It's like a central repository that tracks all changes made to the table. During new reads Apache Spark checks the transaction log to see if any changes were made and makes the required updates to the table. Hence, the single source of truth is enforced, and the user's version of a table is always synchronized to it.
- Governance and compliance: Delta Lake is the default storage format for all operations on Databricks. It's an optimized storage layer that provides the foundation for storing data and tables in the Databricks Lakehouse Platform. It uses mutual exclusion to serialize commits properly. In case of an event, a commit is retired silently. It uses optimistic concurrency; a very common technique used to allow multiple concurrent reads and writes while tables change. This log is a single source of truth and serves as a database level audit table. This transaction log offers a verifiable data lineage. This serves as the pillar of strong governance, audit and compliance needs in the enterprise.
- Business Intelligence: Traditionally, the RDBMS used to be the single source of truth and data warehouses were built on a copy of data from the RDBMS. This introduces latency, staleness and increases the cost of operating with two sources of data instead of one. The introduced complexity increases room for error. This is solved in a lakehouse environment because the business intelligence tools can now be run on the source data itself.
- All types of data: Traditionally, it was very common to use an RDBMS for structured data, denormalize the data into a data warehouse, and use appropriate data stores for images, text, audio and video. This led to the introduction of multiple data stores which increased latency and overall complexity. Lakehouse is one repository for all kinds of data: structured, unstructured and semi-structured data.
- Open principles: Databricks can read and write data directly to and from formats such as Parquet, CSV, JSON, XML, Snowflake, Azure Synapse, Amazon S3, Google Big Query etc. Apache Spark is open source and is compatible with standard open source solutions. Databricks provides APIs so users can access the data directly from a wide variety of tools, frameworks and engines.
- Complete data ecosystem support: The platform supports all modern data workloads including machine learning, data science, data streaming, SQL and data analytics. All these tools are supported on the same data repository. Enterprise is full of use cases which require real-time streaming needs to generate real-time support. Traditionally, there used to be a need for dedicated systems other than the main system to support real-time data applications. Now that need has been eliminated as the platform supports streaming on the common data repository.
Machine Learning
Machine learning is a very innovative field and is very disruptive. However, ML lifecycle is still very new compared to SDLC (Software Development Lifecycle). MLOps (Machine Learning Operations) is to ML what DevOps (Development and IT operations) is to SDLC. Building models and creating pipelines that seamlessly deploy the models into production is quite complex. According to multiple estimates in 2022, more than 60% of models do not make it to production. ML requires working with unstructured data, but we still have the same versioning and governance needs for that data as we have for structured data.
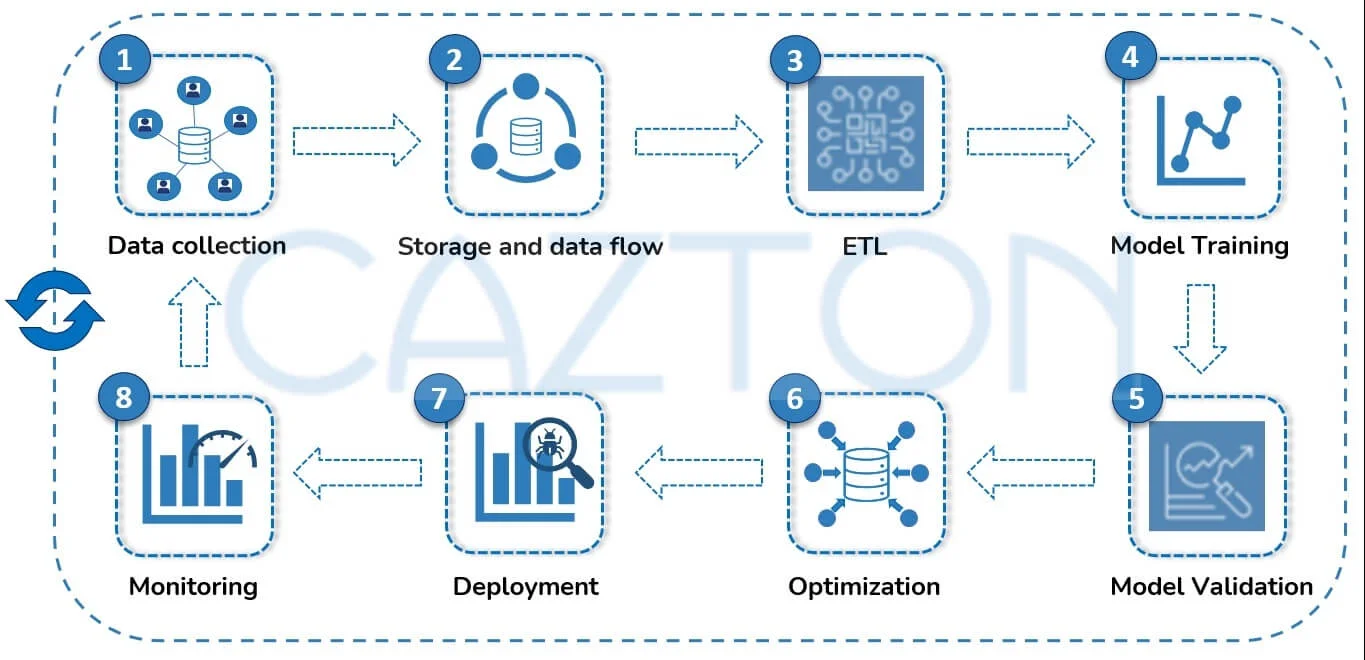
Databricks supports all major ML platforms and technologies. Data scientists and engineers can use R and Python to access the data. MLflow, an open-source platform developed by Databricks, automates the end-to-end ML lifecycle and has become a leader in simplifying the process of standardizing MLOps and deploying the ML models to production. The ML lifecycle can be very complex depending on the underlying business problem we are trying to solve. We need to version different models along with related code, dependencies, visualizations and intermediate data. This is required to be able to track what's the current state of the deployment, what exactly needs to be redeployed and where, and in order to rollback updated models in appropriate cases.
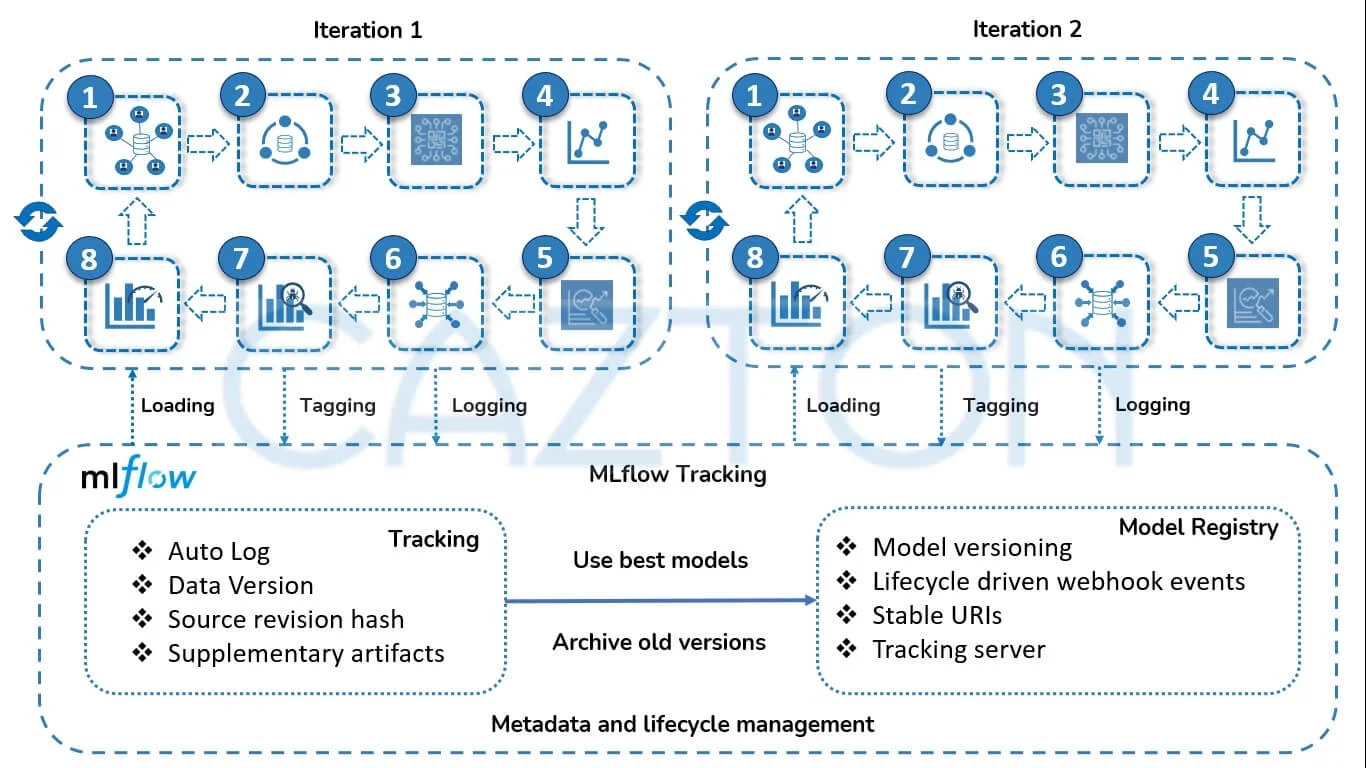
Data lakehouse makes machine learning and data science data-native, which enables us to perform everything from exploratory data analysis, model training and model serving exactly where the rest of the data is being managed. It has everything you need for a team to collaborate and is designed keeping in mind the different personas: data engineer, data scientist, ML engineer, business stakeholder and data governance officer.
Keynote: Best practices on UI, API and Server-side
In our recent keynotes delivered in five continents world-wide we have demonstrated how we can scale the current applications with high performance and at a fraction of the current cost using modern technologies and architecture. The main highlights of this keynote were:
- Scalability best practices
- API best practices
- UI best practices
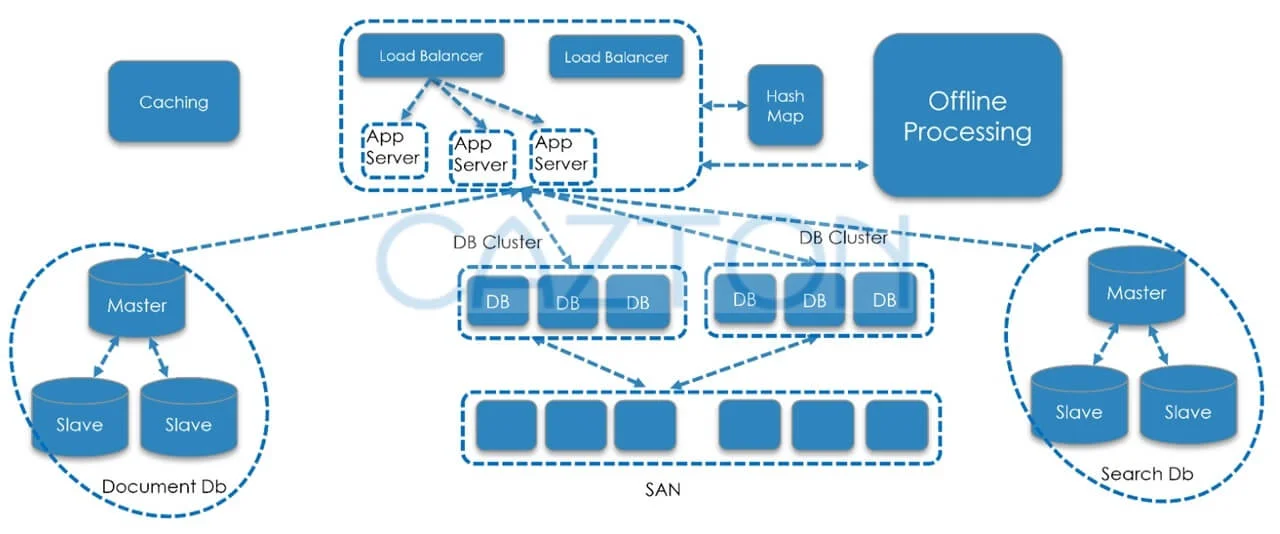
In scalability best practices, the pros and cons of all major database architectures were discussed. The discussions included CAP Theorem, whitepapers on scalability, different types of NoSQL databases along with their use cases, polyglot persistence, scalability bottlenecks and how to avoid them. Finally, the best principles for an auto-scale architecture were discussed. Quite interestingly, the highly scalable architecture was also quite inexpensive to create as well as maintain.
How Cazton Can Help You With Databricks
At Cazton, we help Fortune 500, large, mid-size and start-up companies with Apache Spark and Databricks Lakehouse platform and MLflow development, consulting, recruiting services and hands-on training services. We have an added advantage of creating best practices after witnessing what works and what doesn't work in the industry. Our team includes expert data engineers, data scientists, ML engineers, developers, consultants and architects as well as experts in related technologies. With an expert-led team like ours, we bring the benefit of our network to you. We save our clients a serious amount of effort on tasks they shouldn't be doing by providing a streamlined strategy and updating it timely. We offer the following services:
- Technology Stack: Help create the best machine learning stack using top technologies, frameworks and libraries that suit the talent pool of your organization. This includes Apache Spark, Databricks, PyTorch, TensorFlow, Keras, Scikit-learn and/or others.
- ML Models: Develop models, optimize them for production, deploy and scale them.
- Best Practices: Introduce best practices into the DNA of your team by delivering top quality PyTorch models and then training your team.
- Development, DevOps and automation: Develop enterprise apps or augment existing apps with real time ML models. This includes Web apps, iOS, Android, Windows and Electron.js apps.
- Data strategy: Analyze your business requirements and create a strong, sustainable and predictable data strategy based on proven best practices customized solely for your current and future needs.
- High performance and scale:Create high performance, highly scalable enterprise-level applications utilizing full capabilities of Databricks, Apache Spark and the entire data ecosystem.
- Cloud:Migrate your existing applications to cloud, multi-cloud and hybrid cloud environments.
- MLOps Automation: Automate the entire MLOps process using MLflow (or similar techniques) from development, data ingestion, ETL, model selection, versioning, update, validation, deployment and governance.
- Microservices: Automate your models using Microservices viz. Docker, Kubernetes and Terraform.
- Continuous Integration and Deployment: Build CI/CD pipeline and automate your deployment process.
Cazton Success Stories
Our team has great expertise in building multi-million-dollar enterprise web applications (with billions in revenue per year) for our Fortune 500 clients. Our team includes Microsoft awarded Most Valuable Professionals, Azure Insiders, Docker Insiders, ASP.NET Insiders, Web API Advisors, Cosmos DB Insiders as well as experts in other Microsoft as well as open-source technologies. Our team has mentored professionals worldwide by speaking at top conferences in multiple continents. With the frequent changes in operating systems, platforms, frameworks and browsers; technical folks have a lot to keep up with these days. They can't specialize and be experts in every technology they work on. With an expert-led team like ours, we bring the benefit of our network to you. We save our clients a serious amount of effort on tasks they shouldn't be doing by providing them with a streamlined strategy and updating it when we get more information. We work with Fortune 500, large, mid-size and startup companies and we learn what works and what doesn't work. This incremental learning is passed on to our clients to make sure their projects are successful.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.