Kafka Consulting
- Stream data in real-time: Apache Kafka transforms how enterprises handle streaming data, enabling instant decision-making and operational agility across complex business ecosystems.
- Act on change as it happens: Market shifts, customer behavior, and fraud risks don’t wait. We build Kafka architectures that give you the speed and insight to make instant, informed decisions.
- Built for enterprise scale and security: You need more than experimentation. We deliver secure, fault-tolerant Kafka clusters that scale reliably across your enterprise, without breaking compliance.
- Plan for today, scale for tomorrow: We work with your team to create a phased roadmap that aligns Kafka's potential with your business priorities and transformation goals.
- Performance that grows with you: We optimize Kafka for high throughput, low latency, and cost efficiency, so you're ready for peak demand without over spending on infrastructure.
- Microsoft and Cazton: We work closely with Data Platform, OpenAI, Azure OpenAI and many other Microsoft teams. Thanks to Microsoft for providing us with very early access to critical technologies. Kafka is the backbone of many critical AI agents in the enterprise.
- Top clients: We build tech solutions for top Fortune 500, large, mid-size and startup companies with Big Data, Cloud, and AI development, deployment (MLOps), consulting, recruiting and hands-on training services. Our clients include Microsoft, Broadcom, Thomson Reuters, Bank of America, Macquarie, Dell and more.
Imagine a process which converts unstructured, unreadable pieces of information into something that is extremely valuable for your organization? information that gives you insights into your business, your products, customers, and their preferences. Now imagine getting those insights in real time! We are talking about a process that gives you instant information about an active transaction. Such information is always valuable, isn't it?
Apache Kafka represents the foundational technology that enables this real-time transformation. As a distributed streaming platform, Kafka processes millions of events per second while maintaining the reliability and consistency that enterprise operations demand. However, implementing Kafka successfully requires far more than deploying open-source software.
The difference between a successful Kafka implementation and a costly technical experiment often comes down to expert guidance. Organizations that take the DIY route frequently face performance issues, security risks, and integration roadblocks that stall digital transformation. We help avoid these pitfalls by bringing deep technical expertise and real-world experience to deliver Kafka solutions that are stable, scalable, and aligned with your business goals.
Why Enterprises Struggle with DIY Streaming Platforms
The explosion of IoT devices, mobile applications, and digital customer touchpoints has created an unprecedented demand for real-time data processing. Apache Kafka is the de facto standard used by over 100,000 organizations, yet many enterprises remain trapped in legacy batch processing paradigms that limit their competitive agility.
Current market pressures are forcing executives to prioritize real-time capabilities. Customer expectations for instant responses, regulatory requirements for immediate fraud detection, and supply chain volatility for all demand streaming data architectures. However, a recurring challenge for users has been Kafka's cost and complexity when implemented without proper strategic guidance.
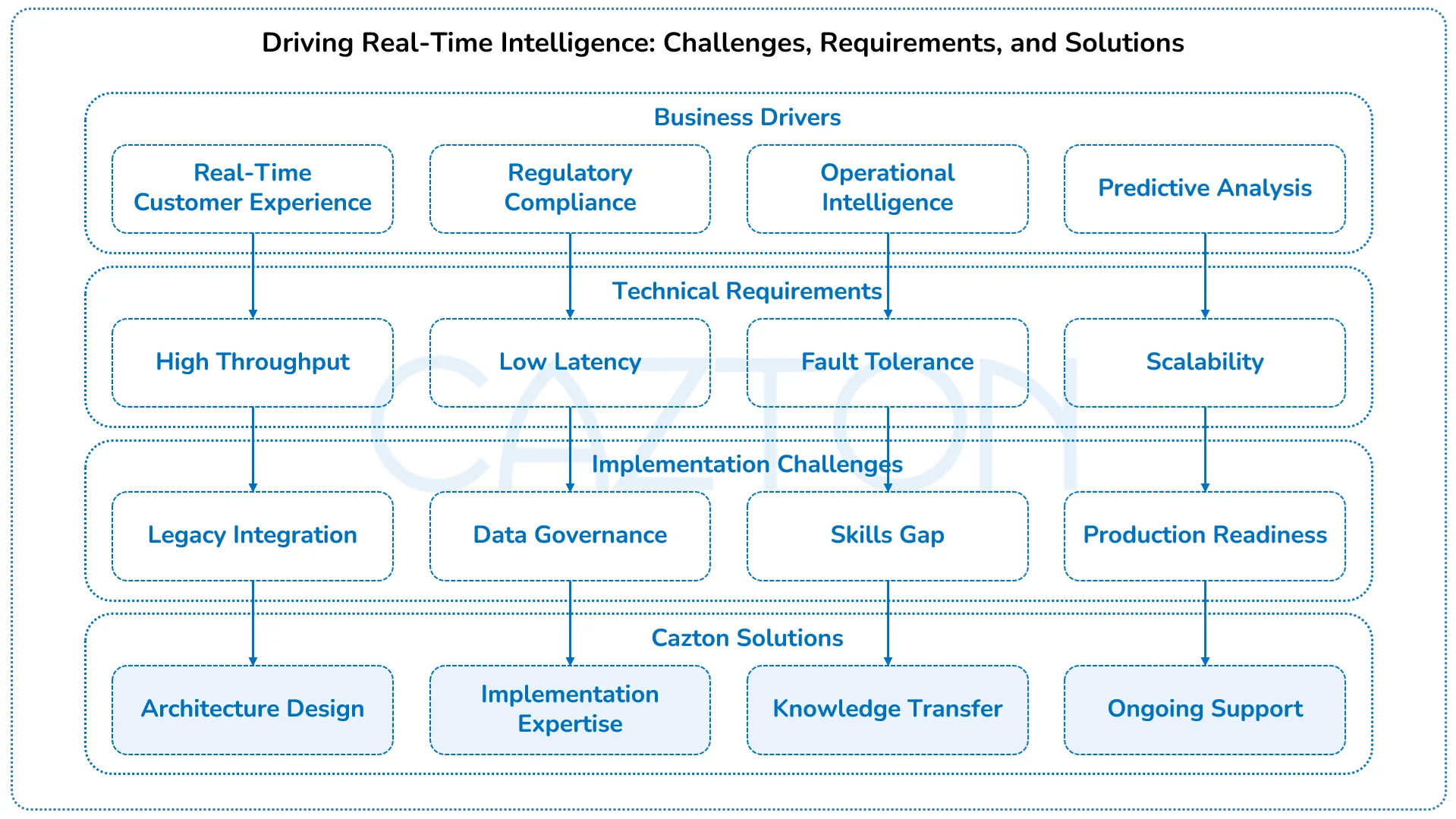
Many organizations hesitate to adopt Kafka because they've witnessed failed implementations at peer companies. These failures typically stem from underestimating the operational complexity, security requirements, and integration challenges that enterprise-grade Kafka deployments entail. The gap between Kafka's potential and successful enterprise adoption is where our consulting expertise becomes invaluable.
We help organizations navigate this complexity by providing strategic roadmaps that align Kafka capabilities with business objectives. Our approach eliminates the trial-and-error cycle that often characterizes internal Kafka initiatives, accelerating time-to-value while avoiding costly missteps.
Understanding Kafka's Role in Modern Data Architecture
Apache Kafka functions as a distributed messaging system that captures, stores, and distributes streaming data across your enterprise infrastructure. Unlike traditional message queues that delete messages after consumption, Kafka maintains a persistent log of all events, enabling multiple applications to process the same data stream for different business purposes.
The core architecture consists of four essential components working in harmony.
- Topics: Your digital data channels - Think of Kafka topics as dedicated channels for specific types of business events. Each sales transaction, customer interaction, or system alert flows through its own topic, creating organized streams of related data.
- Producers: Your data source connectors - Producers are the entry points that capture events from your existing systems and publish them to appropriate topics, ensuring valuable data enters your streaming ecosystem.
- Consumers: Your business applications - Consumer applications subscribe to topics relevant to their function, processing data as it arrives in real-time for analytics, recommendations, fraud detection, and more.
- Brokers: Your resilient data infrastructure - Kafka brokers form the backbone of your streaming platform, reliably storing and transmitting your data streams with a distributed architecture that ensures no single point of failure.
This publish-subscribe model enables powerful use-cases that traditional systems cannot support. For example, a single customer transaction can simultaneously trigger inventory updates, fraud detection algorithms, personalization engines, and analytics dashboards. Each system processes the same event stream independently, creating a responsive ecosystem that adapts to business events as they occur.
Real-world implementations demonstrate Kafka's versatility across industries. Financial institutions use Kafka to process payment transactions and detect fraudulent activity within seconds. E-commerce platforms leverage Kafka to update inventory levels, trigger recommendations, and manage supply chain logistics in real-time. Manufacturing companies employ Kafka to monitor equipment sensors, predict maintenance needs, and optimize production workflows.
Our team specializes in designing Kafka architectures that align with your specific business requirements. We handle complex configuration, security hardening, and integration challenges that ensure your Kafka deployment delivers reliable business value from day one.
How Real-Time AI Transforms Your Business Intelligence
Modern enterprises require AI and machine learning capabilities that operate on real-time data streams rather than static datasets. Apache Kafka serves as the critical infrastructure that enables continuous model training, real-time inference, and automated decision-making at enterprise scale. This integration transforms traditional batch-oriented ML workflows into responsive, adaptive systems that learn and respond to business events as they occur.
Real-time feature engineering becomes possible when ML models consume streaming data directly from Kafka topics. Your data science teams can build feature pipelines that process customer interactions, transaction patterns, and operational metrics in real-time, feeding continuously updated features to prediction models. This approach eliminates the staleness problem that plagues traditional ML systems and enables models to adapt quickly to changing business conditions.
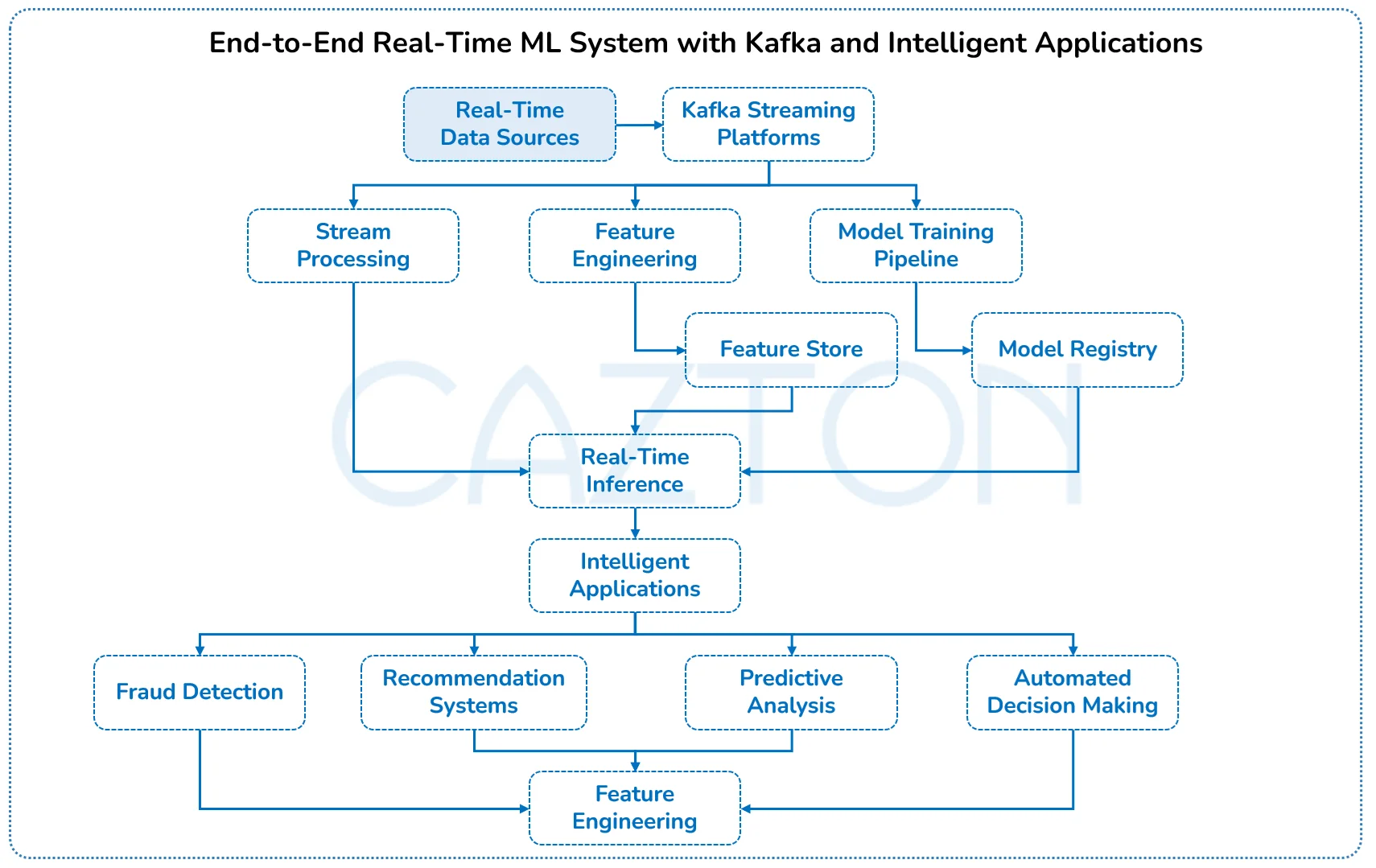
Stream processing frameworks integrated with Kafka enable sophisticated ML workloads including anomaly detection, recommendation engines, and predictive maintenance systems. These implementations process millions of events per second while maintaining model accuracy and response times measured in milliseconds. The combination creates intelligent systems that can detect fraud instantly, recommend products in real-time, and predict equipment failures before they impact operations.
Our team specializes in architecting Kafka-ML integrations that balance performance, scalability, and model governance requirements. We implement streaming ML pipelines that handle model versioning, A/B testing, and performance monitoring while ensuring data quality and regulatory compliance. This expertise enables organizations to deploy production-ready AI systems that deliver measurable business value while maintaining operational excellence.
What Your Organization Needs to Know Before Implementing Kafka
Enterprise environments present unique challenges that off-the-shelf Kafka solutions cannot address. Your organization operates under strict security policies, compliance requirements, and performance standards that demand specialized configuration and ongoing management expertise.
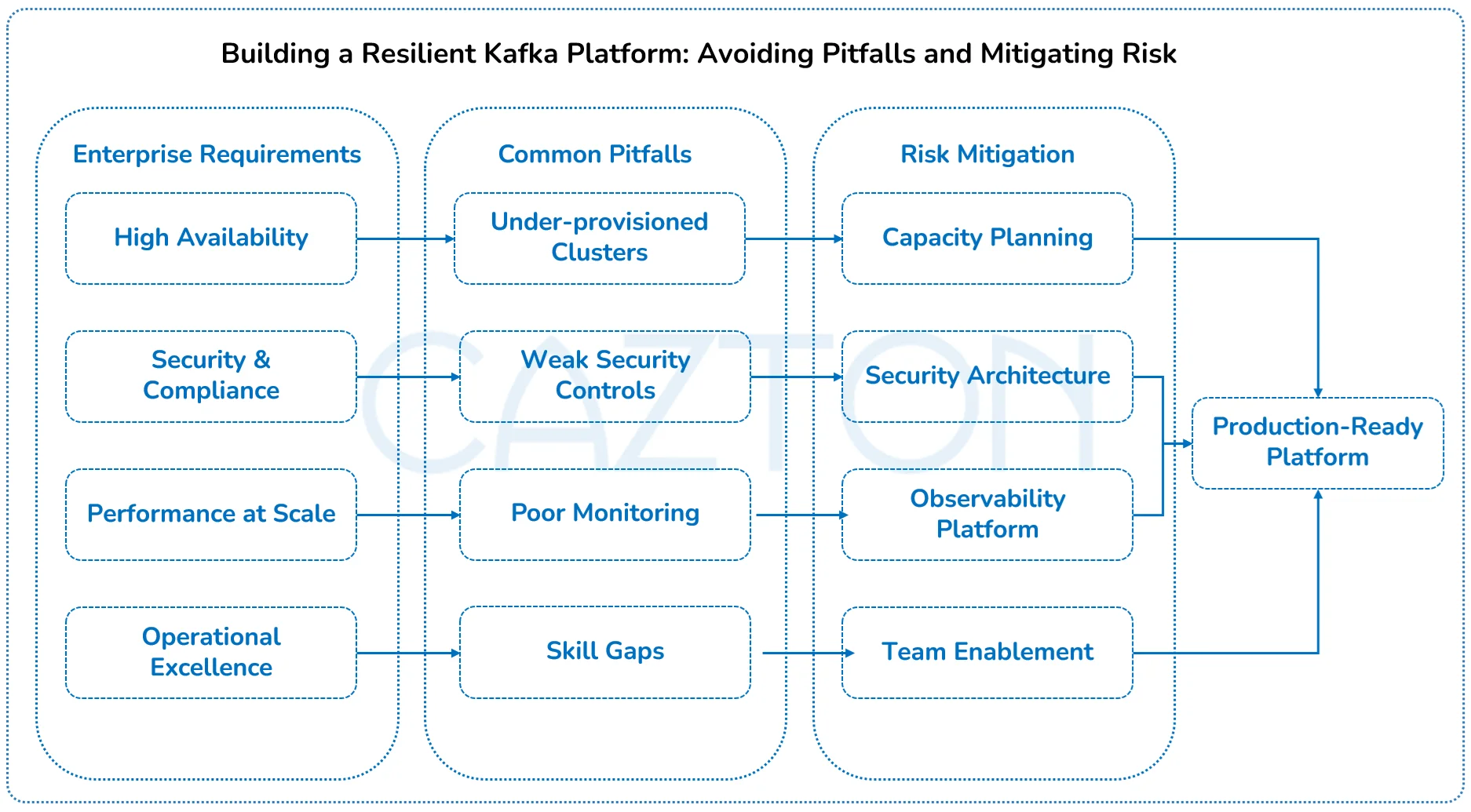
- Security and compliance represent the most critical adoption risks. Standard Kafka deployments lack the enterprise-grade security controls required for handling sensitive customer data, financial transactions, or healthcare records. Implementing proper authentication, authorization, encryption, and audit logging requires deep expertise in both Kafka internals and enterprise security frameworks.
- Scalability and performance issues emerge when Kafka clusters encounter real-world enterprise workloads. What works in development environments often fails under production traffic volumes, data retention requirements, and high availability demands. Poor partition strategies, inadequate replication configurations, and insufficient monitoring can transform Kafka from a performance enabler into a system bottleneck.
- Integration complexity multiplies when connecting Kafka to existing enterprise systems. Legacy databases, ERP platforms, and custom applications each require specific connector configurations, data transformation logic, and error handling mechanisms. Without proper integration architecture, organizations often end up with fragmented data silos that defeat the purpose of streaming data platforms.
- Organizational constraints frequently undermine technical implementations. Teams lack the specialized skills needed to operate Kafka clusters, monitor performance metrics, and troubleshoot complex distributed systems issues. The learning curve for Kafka operations is steep, and many organizations underestimate the ongoing operational overhead required for successful deployments.
Our intervention addresses these risks through proven implementation methodologies that have been field-tested across diverse enterprise environments. We bring both the technical expertise and operational experience necessary to navigate complex enterprise requirements while delivering successful outcomes.
Case Studies
Real-Time Fraud Detection and Risk Management
- Problem: A major financial institution processed fraud detection in overnight batches, resulting in significant losses from fraudulent transactions that occurred throughout the day. Their legacy system couldn't scale to handle increasing transaction volumes or incorporate new data sources for improved detection accuracy.
- Solution: We implemented a real-time fraud detection platform that analyzes transactions as they occur, correlating multiple data streams including transaction history, device fingerprints, and behavioral patterns. The system processes millions of events per second, applying machine learning models to identify suspicious activities within seconds. Custom connectors integrate with core banking systems, payment networks, and third-party risk databases while maintaining strict data governance and regulatory compliance.
- Business impact: The institution reduced fraud losses by detecting and blocking suspicious transactions in real-time. Processing latency decreased from hours to milliseconds, enabling immediate customer notifications and reducing false declines. The platform's scalability accommodates peak transaction periods without performance degradation, while new fraud patterns can be deployed without system downtime.
- Tech stack: Apache Kafka, Kafka Streams, Apache Spark, TensorFlow, PostgreSQL, Redis, Elasticsearch, React.js, .NET, Kubernetes, Azure.
Omnichannel Inventory and Customer Experience
- Problem: A global retailer struggled with inventory synchronization across online and physical stores, leading to overselling, customer dissatisfaction, and lost revenue. Their point-to-point integrations created data inconsistencies and couldn't support real-time inventory visibility across channels.
- Solution: We architected an event-driven inventory management system that captures stock movements from warehouses, stores, and distribution centers in real-time. The platform processes inventory updates, order events, and fulfillment status across all channels, maintaining consistent inventory views for customers and operations teams. Stream processing applications calculate available-to-promise inventory considering in-transit stock, reserved items, and channel-specific rules. Integration with recommendation engines enables personalized product suggestions based on real-time availability and customer behavior.
- Business impact: Inventory accuracy improved dramatically, reducing overselling incidents and improving customer satisfaction scores. Real-time visibility enabled dynamic pricing and promotions based on stock levels. The unified inventory view supported new fulfillment options like buy-online-pickup-in-store, driving additional revenue while reducing shipping costs.
- Tech stack: Apache Kafka, Kafka Connect, ksqlDB, Cassandra, MongoDB, Spring Boot, Angular, Databricks, AWS, Docker.
Patient Monitoring and Clinical Decision Support
- Problem: A healthcare network needed to monitor patient vitals from thousands of IoT devices across multiple facilities, correlate this data with electronic health records, and alert care teams to critical conditions. Their existing infrastructure couldn't handle the data volume or provide timely alerts for intervention.
- Solution: We built a real-time patient monitoring platform that ingests data from medical devices, wearables, and clinical systems. Stream processing applications analyze vital signs, lab results, and medication data to identify deteriorating conditions and potential adverse events. The system maintains HIPAA compliance through end-to-end encryption and audit logging while supporting complex event processing for clinical decision support. Custom dashboards provide care teams with unified patient views and intelligent alerts prioritized by severity.
- Business impact: Early detection of patient deterioration enabled timely interventions, improving clinical outcomes and reducing ICU admissions. Automated alerting reduced response times for critical events while decreasing alert fatigue through intelligent filtering. The platform's scalability supports expansion to additional facilities without architectural changes.
- Tech stack: Apache Kafka, Kafka Streams, HL7 FHIR, PostgreSQL, Apache Ignite, Grafana, React Native, Python Fast API, Kubernetes, GCP.
How Your Complex Requirements Shape Kafka Excellence
Modern organizations require Kafka implementations that extend far beyond basic messaging capabilities. Your business needs custom streaming applications, advanced analytics pipelines, and sophisticated integration patterns tailored to your unique goals and competitive advantages.
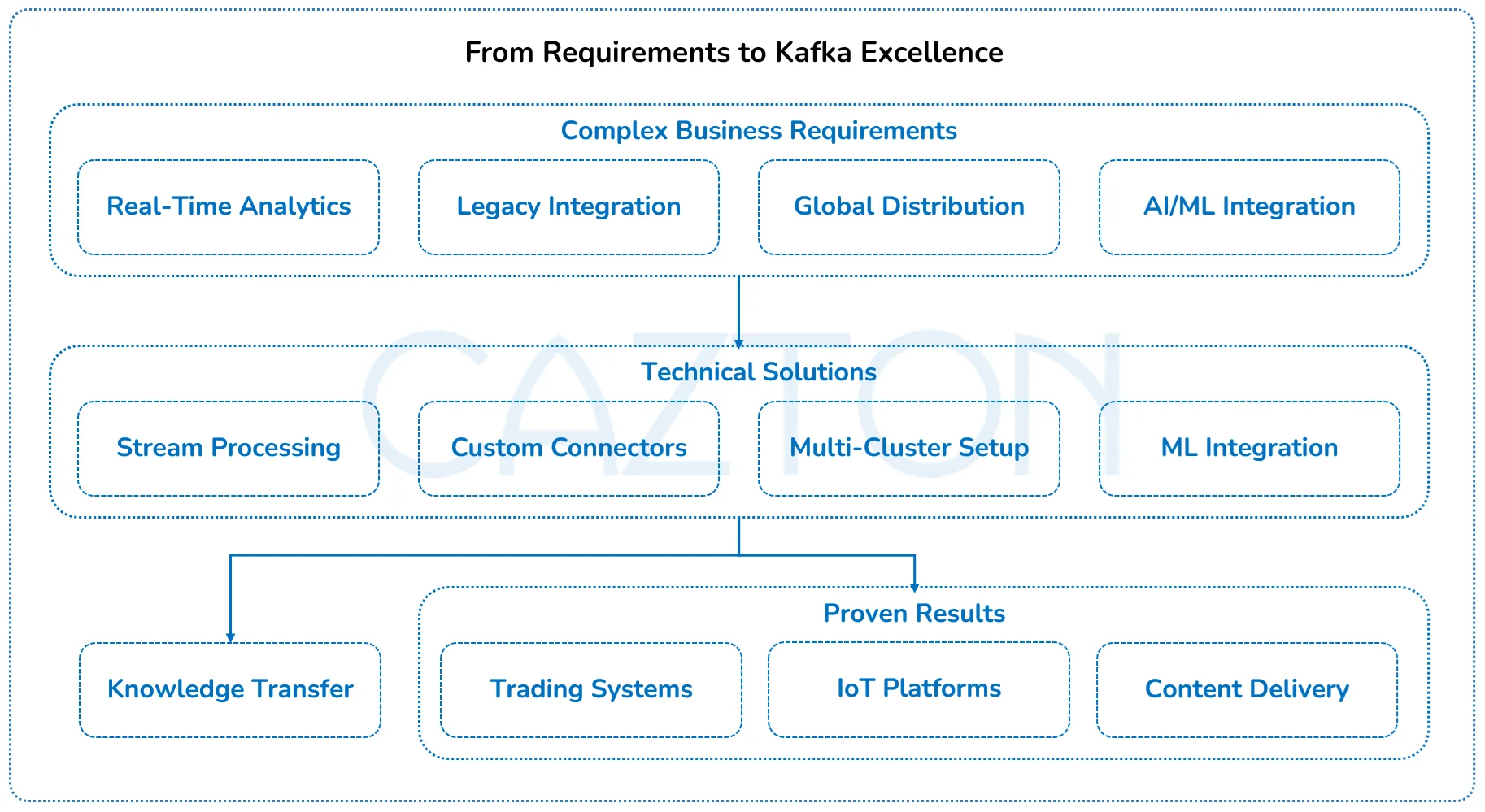
- Advanced stream processing enables complex event correlation, real-time analytics, and automated decision-making that transforms raw data streams into actionable business intelligence. We develop custom Kafka Streams applications that perform complex aggregations, join operations, and stateful processing across multiple data streams simultaneously.
- Custom connector development addresses integration challenges with proprietary systems, legacy databases, and specialized industry platforms. Our team builds enterprise-grade connectors that maintain data consistency, handle error recovery, and provide monitoring capabilities that standard connectors cannot deliver.
- Multi-cluster architectures support global enterprises with distributed operations, regulatory requirements, and disaster recovery needs. We design sophisticated replication strategies, cross-cluster failover mechanisms, and data locality optimizations that ensure business continuity across geographic regions.
- Real-time machine learning integration combines Kafka's streaming capabilities with advanced AI/ML models to enable predictive analytics, anomaly detection, and automated response systems. Our implementations process streaming data through trained models and trigger automated actions based on prediction confidence levels.
Field-tested solutions demonstrate our ability to solve complex enterprise challenges. We've implemented custom Kafka applications for high-frequency trading systems that process millions of market events per second, IoT platforms that manage sensor data from hundreds of thousands of devices, and content delivery networks that optimize user experience through real-time personalization.
Our consulting approach emphasizes knowledge transfer and capability building. We work closely with your technical teams to ensure they understand the architectural decisions, operational procedures, and troubleshooting methodologies necessary for long-term success. This collaborative approach creates sustainable competitive advantages that extend far beyond initial implementation.
How Your Architecture Decisions Impact Kafka Performance
Successful Kafka deployments require careful attention to infrastructure design and data flow architecture. Network topology impacts performance significantly - we design clusters that minimize cross-availability-zone traffic while maintaining fault tolerance. Storage architecture balances performance, durability, and cost through appropriate disk types and retention policies. CPU and memory allocation considers both steady-state and peak workloads to prevent resource exhaustion.
Data serialization strategies affect both performance and evolvability. We implement schema registries that enforce data contracts while enabling controlled evolution. Avro, Protobuf, or JSON schemas are chosen based on performance requirements and ecosystem compatibility. Compression algorithms balance CPU usage with network bandwidth savings. These decisions significantly impact total cost of ownership and operational complexity.
Integration with modern data stacks requires careful API design and error handling. We build resilient producers that handle backpressure gracefully and consumers that process messages idempotently. Circuit breakers prevent cascade failures when downstream systems become unavailable. Distributed tracing provides end-to-end visibility across complex data flows. These patterns ensure reliable data delivery while maintaining system stability.
Legacy system integration presents unique challenges that we address through proven patterns. Change data capture implementations extract events from traditional databases without impacting production workloads. Message transformation bridges incompatible data formats while preserving semantic meaning. Batch-to-stream adapters enable gradual migration from legacy architectures. Our experience with diverse enterprise systems ensures smooth integration regardless of technology vintage.
Executive Implementation Guide for Enterprise Kafka
Successful Kafka adoption requires a strategic implementation approach that aligns technical capabilities with business objectives while building organizational competencies that sustain long-term value creation.
- Phase 1: Foundation and pilot implementation focuses on establishing core Kafka infrastructure and demonstrating value through carefully selected use cases. We work with your team to identify high-impact pilot projects that showcase Kafka's capabilities while building internal expertise and organizational confidence.
- Phase 2: Scaled deployment and integration expand Kafka's role across multiple business functions while deepening integration with existing enterprise systems. This phase emphasizes operational excellence, security hardening, and performance optimization that prepares your infrastructure for enterprise-scale workloads.
- Phase 3: Advanced analytics and automation leverage mature Kafka deployments to enable sophisticated streaming analytics, machine learning integration, and automated decision-making capabilities that create sustainable competitive advantages.
- Governance and capability building remain consistent priorities throughout all implementation phases. We establish operational procedures, monitoring protocols, and knowledge transfer programs that ensure your organization can independently manage and evolve Kafka infrastructure over time.
- Success metrics and KPIs provide objective measures of implementation progress and business value creation. We help establish meaningful metrics that track technical performance, operational efficiency, and business outcomes that justify continued investment in streaming data capabilities.
Our roadmap approach recognizes that enterprise transformation is an iterative process that requires flexibility, patience, and sustained commitment. We serve as your strategic partner throughout this journey, providing expertise, support, and guidance that ensures successful outcomes at every stage.
How Cazton Can Help You With Kafka
The journey from traditional batch processing to real-time streaming architecture represents one of the most impactful transformations that modern enterprises can undertake. However, this transformation requires more than technology deployment; it demands strategic partnership with experts who understand both the technical complexity and business implications of streaming data platforms.
We bring deep expertise in designing, implementing, and optimizing Apache Kafka deployments for enterprise environments. Our consultants have architected streaming platforms processing billions of events daily for organizations across industries. We understand the complexities of distributed systems and the nuances of enterprise requirements, ensuring your Kafka implementation delivers reliable, scalable, and secure data streaming capabilities.
Our approach combines strategic planning with hands-on implementation expertise. We work closely with your teams to understand business objectives, assess technical requirements, and design solutions that balance immediate needs with long-term scalability. Our proven methodologies reduce implementation risk while accelerating time-to-value. We don't just build systems; we enable your organization to operate and evolve them independently through comprehensive knowledge transfer and ongoing support.
Here are our Kafka offerings:
- Kafka architecture and design: Custom streaming architectures aligned with your business requirements and technical constraints.
- Implementation and migration services: End-to-end deployment including infrastructure setup, security configuration, and data migration.
- Performance optimization: Comprehensive tuning of producers, brokers, and consumers for maximum throughput and minimum latency.
- Custom connector development: Purpose-built integrations with legacy systems, databases, and cloud services.
- Stream processing applications: Kafka Streams and ksqlDB implementations for real-time analytics and data transformation.
- Multi-region and hybrid cloud solutions: Distributed deployments across data centers and cloud providers with disaster recovery.
- Security and compliance implementation: Enterprise-grade security controls, encryption, and audit logging for regulated industries.
- Monitoring and observability platforms: Comprehensive monitoring solutions providing real-time visibility and alerting.
- Training and enablement programs: Role-based training for developers, operators, and architects.
- 24/7 support and managed services: Ongoing operational support and platform management.
- Proof of concept development: Rapid prototypes demonstrating Kafka's value for specific use cases.
- Platform modernization: Migration from legacy messaging systems to modern event-driven architectures.
The competitive advantage that real-time data processing provides continues to grow as market conditions become more dynamic, and customer expectations evolve. Organizations that delay streaming data adoption risk falling behind competitors who can respond instantly to market changes, customer needs, and operational challenges.
Ready to transform your data infrastructure into a competitive advantage?
Contact us today to discuss your specific requirements and learn how we can accelerate your journey to real-time enterprise capabilities. Schedule a strategic consultation today to explore how Apache Kafka can drive measurable business outcomes for your organization.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.