Lambda Architecture
- Lambda Architecture is a popular enterprise architecture that can be used to create high-performance and scalable software solutions.
- In Lambda architecture, data is ingested into the pipeline from multiple sources and processed in different ways. The processed data is then indexed which can be used for data analytics.
- At Cazton, our experts have years of real-world hands-on experience in implementing lambda architectures. We help Fortune 500, large and mid-size companies build modular, scalable, maintainable and testable software solutions.
Since the evolution of a wide variety of devices, the volume of data being captured has grown. The IoT is emerging as a key enabler of our digital future, and global spending on IoT and Smart devices will increase tremendously in the next few years. There has been a widespread adoption of different types of technologies in industries like banking and investment services, education, healthcare, insurance, and many others. What this means is that data is growing and the need to store, manage and process it has become crucial.
As data grows, companies will face two major problems: storage and processing. Traditional RDBMS is not an ideal and scalable approach to handle such large volumes (terabytes or petabytes) of data. Such data needs to be processed so that it can be turned into valuable information that can help organizations make crucial futuristic decisions. This is where Big Data technologies like Hadoop and Spark come in and help organizations solve these problems.
Hadoop is a highly scalable open-source framework, which allows processing and storage of structured and unstructured complex data (big data) across clusters of computers. Its unique storage mechanism over distributed file system maps data wherever it is located on a cluster. The speciality of Hadoop is that it can scale from one server to hundreds of servers and can still perform well. Check out our article on Hadoop and HDFS for more information.
Hadoop internally uses MapReduce mechanism for processing large datasets; however, this approach handles data processing in batches where the data is divided into small sets and shared across different computers in the cluster for processing. Batch processing is time consuming as it happens on the disk and it is not ideal when you want real-time information. This is where Spark can help process data in-memory 100x faster than Hadoop. The adoption of Spark in the industry has increased due to its ecosystem, high speed data-stream processing, fault-tolerance, and the various advantages it offers.
Both Hadoop and Spark are the most preferred technologies currently in the big data industry. Hadoop is famous for its MapReduce mechanism, reliability and batch processing. Whereas Spark is famous for its fault-tolerance, fast and near real-time processing, but there can be scenarios where both batch and real-time data processing are required. Imagine building a data pipeline, which ingests data from different sources. The pipeline is divided into two different processes. One that processes data in real-time and the other one in batches. This is where Lambda architecture helps solve problems encountered in such scenarios. Let's continue and understand what Lambda architecture is, its implementation and various advantages it offers.
What is Lambda Architecture?
The term Lambda in the word Lambda Architecture comes from the mathematical lambda symbol. The picture of the Lambda architecture shown below represents the tilted lambda symbol. The application of this architecture is not specific to Spark or Hadoop. It is a generic architecture that can be applied with any set of technologies. In this article, we will see how Lambda architecture can be used with Spark and other big data technologies.
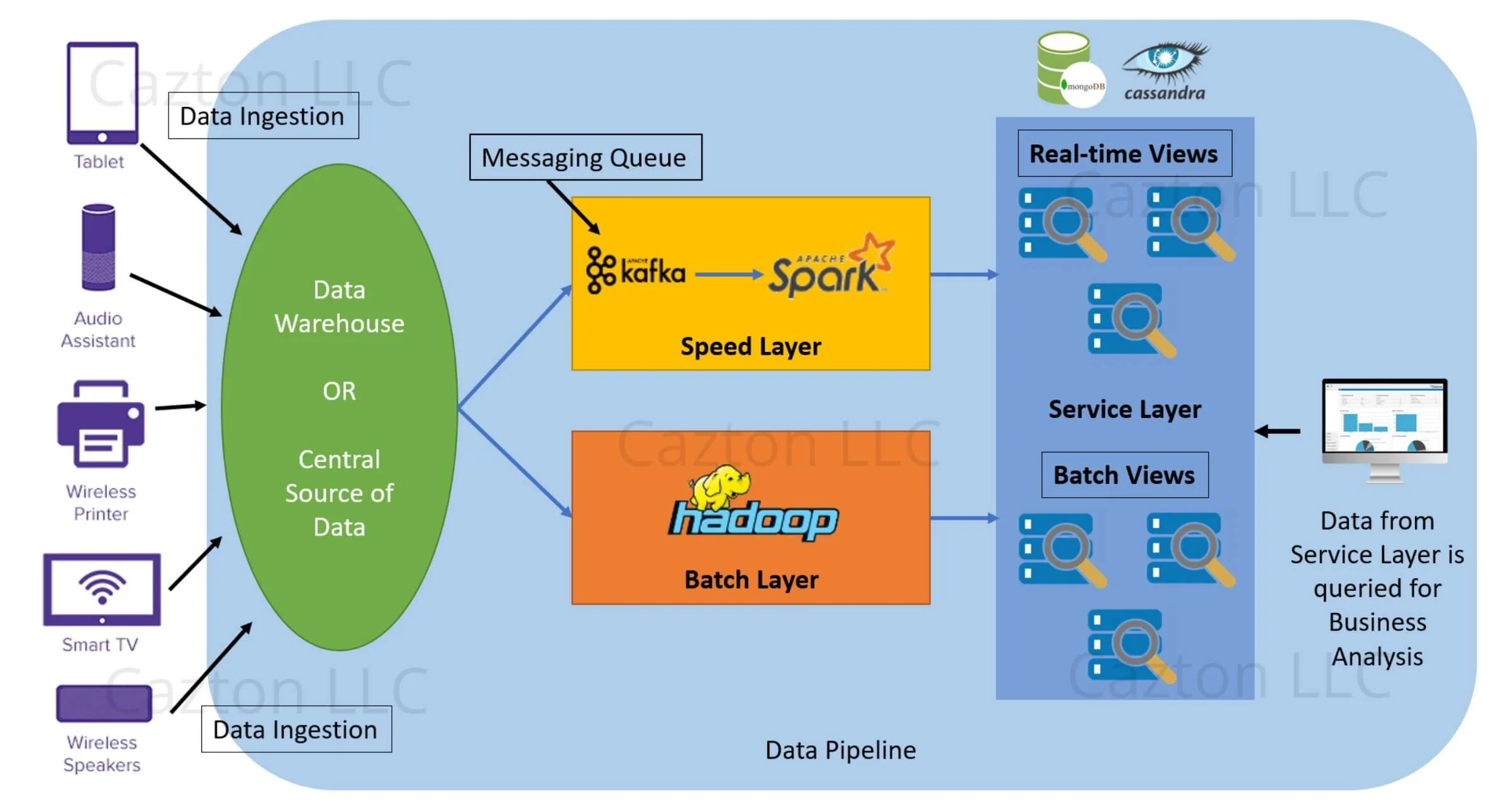
Lambda architecture can be divided into different layers discussed in detail below:
Batch Layer
In this layer, data that comes from a data warehouse or a central data source and is divided into small batches and sent for processing. One can easily rely on Hadoop for this layer and can use HDFS for storing the data and MapReduce for batch processing. Batch processing can be slow and can take up to several hours to complete; however, this layer is extremely reliable for processing large datasets and get detailed insights. Once a batch is processed, batch views are created and pushed to Service layer for storage and querying.
Speed Layer
This layer accepts continuous streams of data and can use technologies like Apache Spark or Storm for real-time and near real-time processing. The data that is pushed to this layer is quickly processed within milliseconds to seconds and the corresponding real-time views are pushed to the Service layer. This layer not only helps in processing data at a faster speed, but also perform real-time analytics.
Service Layer
Data from both batch and speed layer are pushed into this layer for indexing. Database technologies like Cassandra, HIVE, MongoDB can be used to store and manage the indexed data. The data stored in this layer can be further queried by any inhouse application for business analytics.
Implementation of Lambda Architecture with Hadoop & Spark
This section describes the entire process shown in the diagram above.
- Large volumes of data is being generated from different types of devices. These devices are connected to the central data source where they push raw data into it.
- The data source is responsible for storing structured, semi-structured, unstructured data in raw format.
- Data from this warehouse is pushed into both the layers "Batch" & "Speed" for different types of data processing.
- The batch layer divides the data into batches and processes them. The output is batch views, which is then pushed to service layer. Hadoop sits in this layer, which is responsible for storing, managing and processing the data.
- The speed layer is responsible for processing data at real-time. Kafka acts as a messaging queue, so any data passed from the data sources first hits Kafka and then pushes the data to Spark for near real-time processing. Once the data is processed, real-time views are pushed to service layer.
- The service layer may hold any database technology like Cassandra or MongoDB and is responsible for creating indexes from the Batch and Real-time views.
- Any inhouse or external applications can then perform ad-hoc queries on those indexes and display the information for business analytics.
Advantages of Lambda Architecture
- Balanced & Flexible: This architecture keeps a balance on both real-time and reliability. One can perform real-time analytics or do a detailed analysis based on their requirements. It is a simple architecture to understand and flexible enough to maintain.
- Immutable Data: The data that is being passed to the batch layer is often coming from an immutable data source, meaning the data being passed cannot be updated or deleted.
- Best for business analytics: Due to data immutability, the data that is stored in batch views can be used for business analytics as it can give better insights. As new batch updates are available, users will be able to view both old data as well as new one. This helps in better data analysis.
- Improve Extraction Algorithm: We can enhance the data extraction algorithm and apply it on the old dataset. This is extremely helpful in agile and startup environments.
- Fault Tolerance: The data that comes in for real-time processing is mutable and there are chances of data corruption or loss of data due to human or application errors; however, since the data is also being processed in batches, it is still being persisted in the end. We may lose real-time analysis, but batch processing can help recover the data and perform analysis in future.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.