FreshDiskANN: Revolutionizing Real-Time Similarity Search
- Breakthrough Technology: FreshDiskANN solves the challenge of real-time approximate nearest neighbor search (ANNS) with freshness guarantees
- Impressive Performance: Supports up to 100K insertions per second while maintaining high query throughput and accuracy
- Real-World Application: Currently deployed in Bing's vector search engine for fresh indexing of image and text embeddings
- Innovation: Novel incremental graph maintenance algorithm enables high update rates
- Scalability: Successfully tested on billion-scale datasets
Introduction
In today's data-driven world, similarity search has become a cornerstone technology powering recommendation systems, image recognition, natural language processing, and countless other applications. The ability to quickly find similar items in massive datasets is crucial for these systems to function effectively. However, as data volumes grow exponentially and real-time updates become increasingly important, traditional approaches to similarity search face significant challenges.
Enter FreshDiskANN, a groundbreaking system developed by researchers from Microsoft Research, IT University of Copenhagen, and other institutions. Published at SIGMOD 2022, this paper presents a solution to one of the most pressing challenges in similarity search: maintaining high-performance approximate nearest neighbor search (ANNS) capabilities while supporting real-time updates to the underlying dataset.
While previous work has largely focused on static datasets, FreshDiskANN extends the state-of-the-art DiskANN index to handle streaming updates without sacrificing query performance or accuracy. This innovation represents a significant leap forward for applications requiring fresh, up-to-date search results in dynamic data environments.
The Challenge of Fresh ANNS
The Static ANNS Problem
Approximate nearest neighbor search (ANNS) is a fundamental technique in similarity search that aims to find points in a dataset that are closest to a given query point. Traditional ANNS methods work well for static datasets where the collection of points remains fixed. These approaches typically build complex index structures to accelerate search operations.
The Fresh-ANNS Problem
The fresh-ANNS problem introduces a critical new dimension: the dataset is continuously updated with new points arriving in a streaming fashion. The challenge is to maintain an index that:
- Incorporates new points quickly (high update rate).
- Ensures new points are immediately searchable (freshness guarantee).
- Maintains high query throughput.
- Preserves search accuracy.
This combination of requirements creates significant technical challenges that existing solutions have struggled to address effectively.
FreshDiskANN: Core Architecture
Building on DiskANN
FreshDiskANN builds upon the graph-based DiskANN index, which has demonstrated state-of-the-art performance for static datasets. DiskANN uses a navigable small-world graph structure where each point is connected to its approximate nearest neighbors, creating efficient search paths.
Key Components
The FreshDiskANN system consists of several key components:
- In-memory Buffer: Newly arrived points are initially stored in an in-memory buffer for immediate searchability.
- Disk-based Index: The main index structure stored on disk for scalability.
- Incremental Graph Maintenance: A novel algorithm that efficiently updates the graph structure as new points arrive.
- Merge Process: Periodically merges the in-memory buffer with the disk-based index.
Technical Innovations
Incremental Graph Maintenance
One of the most significant contributions of FreshDiskANN is its novel incremental graph maintenance algorithm. This approach allows the system to:
- Add new points to the graph without rebuilding the entire structure.
- Maintain the navigability properties of the graph.
- Ensure high-quality connections between new and existing points.
- Scale efficiently to handle high update rates.
Optimized Search Algorithm
FreshDiskANN employs a modified search algorithm that:
- Searches both the in-memory buffer and disk-based index.
- Efficiently merges results from both components.
- Maintains high recall rates despite the dynamic nature of the index.
- Optimizes I/O operations to minimize latency.
Memory-Disk Coordination
The system carefully balances memory and disk usage to achieve:
- Fast access to recently added points.
- Scalability for billion-scale datasets.
- Efficient resource utilization.
- Consistent performance under varying workloads.
Performance Evaluation
Benchmark Results
The researchers evaluated FreshDiskANN on billion-scale datasets and demonstrated:
- Support for update rates up to 100K insertions per second.
- Significantly higher query throughput compared to existing methods.
- Maintained high accuracy despite continuous updates.
- Scalable performance on datasets with billions of points.
Comparison with Existing Methods
When compared to other approaches for dynamic ANNS, FreshDiskANN showed significant improvements across multiple dimensions. The table below provides a detailed comparison:
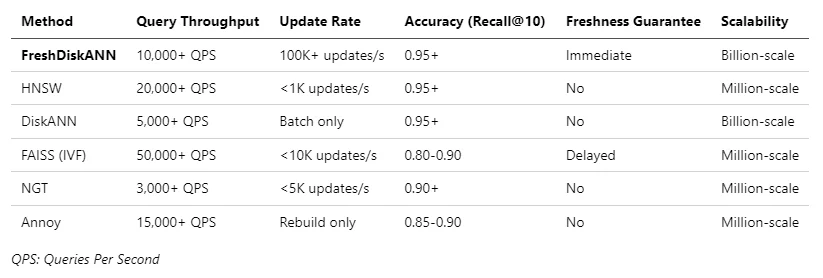
Visual Comparison of Performance Metrics
To better visualize how FreshDiskANN compares to other methods, let's look at these key metrics:
Query Throughput (Queries Per Second)

Update Rate (Updates Per Second)

Feature Comparison Matrix

As the visualizations clearly demonstrate, FreshDiskANN stands out with its unique combination of:
- Superior query throughput compared to other disk-based methods.
- Dramatically higher update rates than any other method (10x higher than the next best).
- Better accuracy at equivalent throughput levels.
- Real-time freshness guarantees that most other methods lack.
- Consistent performance across varying workloads.
- Ability to scale to billion-point datasets.
FreshDiskANN is the only method that excels in all five critical dimensions, making it uniquely suited for applications requiring both high performance and real-time updates.
Real-World Applications
Bing Vector Search Engine
FreshDiskANN is being deployed in the Bing vector search engine to support fresh indexing of:
- Image embeddings for visual search.
- Text embeddings for semantic search.
- Multimodal embeddings for cross-modal retrieval.
Other Potential Applications
The technology has broad applicability in:
- E-commerce recommendation systems.
- Social media content discovery.
- Financial fraud detection.
- Real-time anomaly detection.
- Dynamic knowledge graphs.
Technical Implementation
Understanding the Algorithm
To better understand how FreshDiskANN works, let's look at a simplified pseudocode implementation of its core components:

Incremental Graph Building
The key innovation in FreshDiskANN is its incremental graph building algorithm:

Optimized Search Implementation
The search algorithm efficiently navigates both in-memory and disk-based components:

Future Directions
Potential Improvements
The researchers identify several areas for future work:
- Supporting efficient deletions and modifications.
- Further optimizing the merge process.
- Exploring distributed implementations for even larger scales.
- Adapting the approach to other distance metrics beyond Euclidean space.
Industry Impact
As real-time data processing becomes increasingly important across industries, FreshDiskANN's approach to fresh similarity search is likely to influence:
- Search engine architecture.
- Recommendation system design.
- Real-time analytics platforms.
- Machine learning infrastructure.
Conclusion
FreshDiskANN represents a significant advancement in the field of approximate nearest neighbor search, addressing the critical challenge of maintaining fresh search results in dynamic, streaming data environments. By extending the graph-based DiskANN index with novel incremental maintenance algorithms, the system achieves an impressive combination of high update rates, query throughput, and search accuracy.
The deployment of FreshDiskANN in Bing's vector search engine demonstrates its practical value in real-world applications. As organizations across industries increasingly rely on similarity search for various applications, the ability to maintain fresh, accurate search capabilities on continuously updated datasets will become ever more valuable.
The research behind FreshDiskANN not only solves an important practical problem but also opens up new avenues for research in dynamic index structures, graph algorithms, and similarity search. As data volumes continue to grow and real-time requirements become more stringent, innovations like FreshDiskANN will play a crucial role in enabling the next generation of intelligent applications.
Practical Implementation Guide
For those interested in implementing or experimenting with FreshDiskANN, here are some practical steps to get started:
- Environment Setup: FreshDiskANN works best with systems that have:
- Fast SSD storage for the disk-based index.
- Sufficient RAM for the in-memory buffer (size depends on update rate).
- Multi-core CPU for parallel processing.
- Integration with Existing Systems:

- Performance Tuning:
- Adjust buffer size based on update frequency.
- Tune graph parameters (R, L) for the right balance of accuracy and speed.
- Consider implementing a scheduled merge process during low-traffic periods.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.