AI Governance
- Governance-first approach: Treats GenAI deployment as a capability-building exercise rather than a technology procurement, prioritizing executive accountability, structured review gates, defined success criteria, and compliance planning before any model reaches production.
- Failure taxonomy: Organizes enterprise GenAI breakdowns into five categories: governance, evaluation, technical and architectural, operational, and organizational talent. These are prioritized by frequency and preventability, with governance gaps identified as a frequently observed and highly addressable root cause.
- Stage-gate framework: Moves GenAI initiatives through five phases: problem qualification, proof of concept, pilot, production deployment, and optimization and scaling. Each phase is governed by a specific gate question and documented go or no-go criteria that must be satisfied before advancement.
- Operational readiness framework: Combines a production checklist spanning monitoring, incident response, compliance, and fallback infrastructure with a build, buy, partner, or wait matrix that aligns each path's risks and governance emphasis to an organization's specific capabilities and constraints.
GenAI in the Enterprise: Common Failure Patterns, Root Causes, and Governance Frameworks for Reliable Deployment
Insights from enterprise GenAI deployment challenges
About the Author:
As CEO of Cazton, I've worked directly with enterprises navigating the transition from GenAI pilots to production-grade systems. This analysis synthesizes patterns observed across deployments, combining published research with real-world implementation experience.
Executive Summary
As enterprise adoption of generative AI has accelerated since 2023, a persistent pattern has emerged: the hardest blockers are rarely about the models themselves. They're about ownership, evaluation, governance, and operational readiness.
In our work helping organizations build production-ready GenAI systems, we've identified recurring patterns across governance, evaluation, and operational readiness. This analysis combines insights from published sources with frameworks we've developed and refined through direct client engagements. Our focus is on the five most common failure categories and, more importantly, the governance structures, evaluation practices, and operational controls that we've seen distinguish successful deployments from those that stall.
Key findings from our work with enterprise clients:
- Governance gaps, more than model limitations, are a frequent challenge we help clients address. Organizations that approach GenAI as a capability build rather than a technology procurement tend to achieve better outcomes because this framing forces early attention to accountability, success criteria, and operational readiness.
- Evaluation practices often need refinement. When helping clients design evaluation frameworks, we emphasize that lab-environment accuracy rarely predicts production performance. Domain-specific, adversarial, and longitudinal evaluation frameworks provide the instrumentation organizations need for confident deployment decisions.
- The pilot-to-production gap is structural, not incidental. In our experience, this gap reflects under-investment in integration architecture, operational monitoring, fallback design, and organizational change management.
- Talent gaps exist but are often misdiagnosed. We frequently find that the critical shortage is not in "AI engineers" but in professionals who combine domain expertise, evaluation rigor, and systems-thinking.
- Audio, image, and video modalities carry distinct and often underestimated risk profiles that require modality-specific governance.
This report includes: A failure mode taxonomy, a stage-gate framework for GenAI programs, an operational readiness checklist, and a decision framework for build, buy, partner, or wait decisions. These are all tools we've refined through multiple enterprise engagements.
What the Evidence Shows: Scope of the Problem
Reported Failure Rates: What They Mean and Don't Mean
Multiple studies report high failure rates for enterprise GenAI initiatives, but these figures require careful interpretation.
Synthesis:
Many GenAI initiatives stall between pilot and production because governance structures weren't built alongside the technology. The good news: these are identifiable, addressable mechanisms: ownership, gates, evaluation discipline, and operational readiness.
Note for readers: Beware of any source, including this one, that cites a single, precise failure rate for "GenAI projects" as a category. Definitions of failure, project scope, industry context, and measurement methodology vary significantly across studies. Precision in this domain is often false precision.
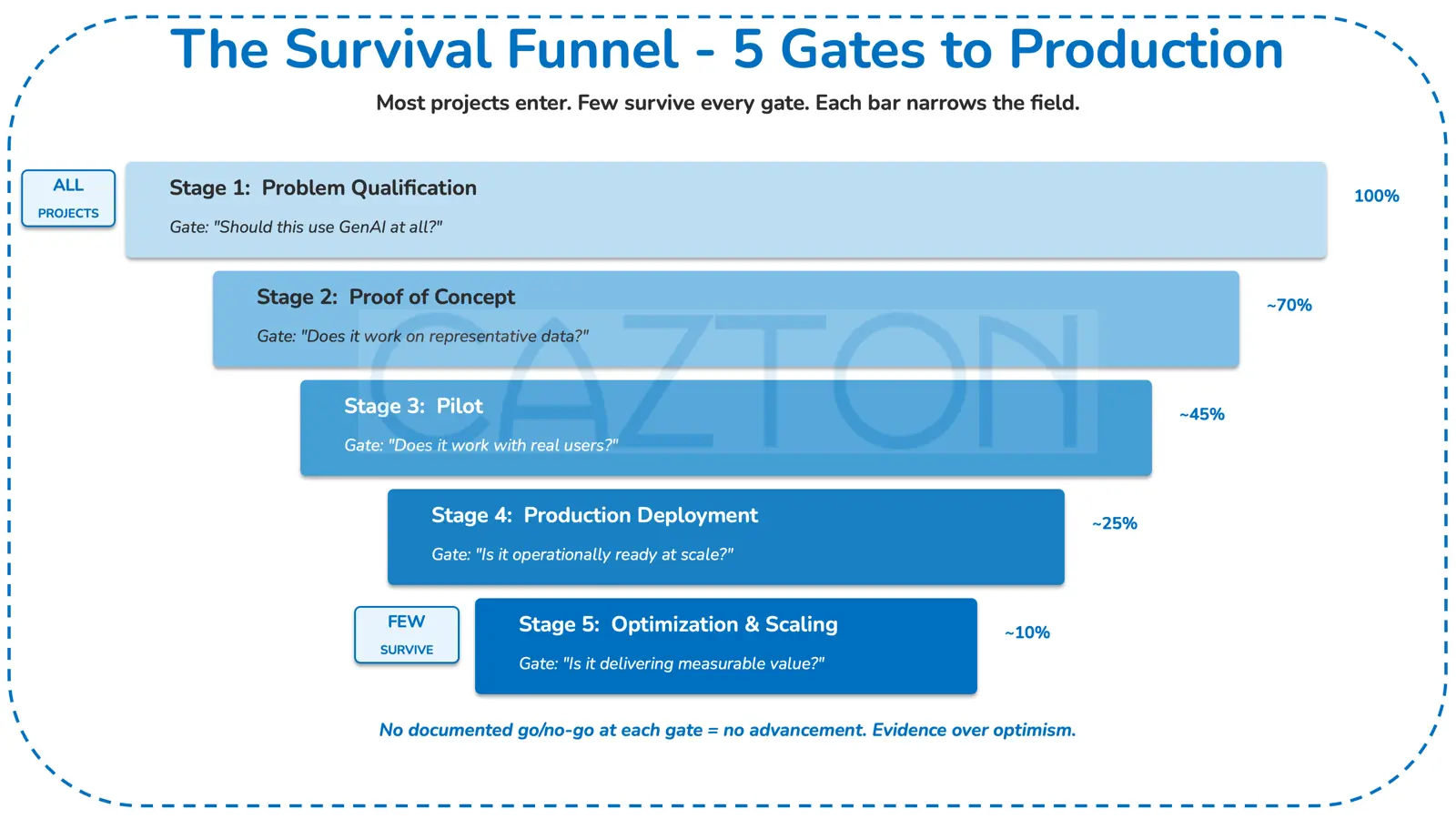
The Pilot-to-Production Gap
A consistent pattern across enterprise deployments: GenAI systems that perform well in controlled environments often struggle when exposed to production conditions. Understanding why this happens, and designing for it, is central to reliable deployment.
Common contributors to this gap:
- Data distribution shift: Production data is messier, more diverse, and more adversarial than test data
- Integration complexity: LLM outputs must interface with existing systems, workflows, and human decision processes
- Evaluation mismatch: Metrics used in development (e.g., BLEU, ROUGE, perplexity) do not map to business value metrics
- Operational absence: No monitoring, no drift detection, no fallback procedures, no feedback loops
- Organizational readiness: End users were not consulted, trained, or given agency in the design process

Failure Mode Taxonomy
The following taxonomy organizes observed failure patterns into five categories, prioritized by frequency and preventability based on both literature synthesis and patterns we've observed helping clients navigate these challenges.
Governance Failures (Most Common, Most Preventable)
In our advisory work, governance gaps are often the first area we address, and they are typically the fastest to resolve with the right framework.
| Failure Mode | Description | Observable Indicator |
|---|---|---|
| No executive sponsor with operational accountability | Project is "owned" by innovation lab or IT without business-line accountability | No named individual whose performance review includes GenAI outcomes |
| Absent or ceremonial review gates | No structured decision points between phases | Projects move from POC to production without documented go or no-go criteria |
| Undefined success criteria | "We'll know it when we see it" | No pre-registered metrics, thresholds, or evaluation timeline |
| Compliance and legal review deferred | "We'll figure out legal later" | No legal, compliance, or risk review before production data exposure |
| Vendor dependency without exit planning | Single-vendor lock-in with no fallback | No documented switching costs, data portability plan, or alternative architecture |

Evaluation Failures (Most Technically Consequential)
When designing evaluation frameworks for clients, we emphasize that proper evaluation is not a gate to pass through once. It is an ongoing operational discipline.
| Failure Mode | Description | Observable Indicator |
|---|---|---|
| Lab-only evaluation | Model tested only on curated, clean datasets | No production-environment testing, no adversarial evaluation |
| Hallucination tolerance undefined | No organizational decision on acceptable hallucination rates by use case | Same model deployed for low-stakes content generation and high-stakes decision support |
| Human evaluation absent or unstructured | No systematic human review of model outputs | Reliance on automated metrics alone; no domain expert review protocol |
| Evaluation is one-time, not continuous | Model evaluated at launch, never again | No drift monitoring, no periodic re-evaluation, no regression testing |
| Accuracy conflated with usefulness | "The model is 90% accurate" treated as sufficient | No measurement of downstream business impact, user trust, or error cost |
On hallucination rates: Published benchmarks consistently report non-trivial hallucination rates across current-generation LLMs, with figures varying significantly by model, task type, domain specificity, and prompting strategy. For high-stakes enterprise applications (legal, medical, financial), even low hallucination rates may be operationally unacceptable without human-in-the-loop verification. We help organizations establish use-case-specific hallucination tolerance thresholds rather than relying on general benchmarks.
Technical and Architectural Failures
| Failure Mode | Description | Observable Indicator |
|---|---|---|
| RAG implemented without retrieval quality measurement | Retrieval-Augmented Generation deployed but retrieval precision and recall never measured | Users report irrelevant or contradictory outputs; no retrieval metrics in dashboards |
| Prompt engineering treated as sufficient architecture | Complex business logic encoded in prompts rather than system design | Fragile outputs that break with minor input variations; no version control on prompts |
| Context window limitations unaddressed | Long-document or multi-turn use cases exceed effective context utilization | Performance degrades on longer inputs; "lost in the middle" phenomena undetected |
| Fine-tuning without data governance | Models fine-tuned on unvetted, unlicensed, or biased datasets | No data provenance documentation; potential IP or bias liability |
| No fallback architecture | System has no graceful degradation path when model fails or is unavailable | Hard failures, user abandonment, or silent error propagation |
On RAG and RAFT: Retrieval-Augmented Generation and Retrieval-Augmented Fine-Tuning represent meaningful architectural improvements for grounding LLM outputs in enterprise knowledge. However, they are not self-correcting. In our implementation work, we ensure RAG systems include ongoing measurement of retrieval quality (precision, recall, relevance scoring), document freshness management, and chunk-size optimization. Without these operational disciplines, organizations often find that retrieval errors compound rather than correct generation errors.
Operational Failures
| Failure Mode | Description | Observable Indicator |
|---|---|---|
| No production monitoring | Model deployed without observability infrastructure | No dashboards for latency, error rates, output quality, cost per query |
| Cost model absent or incomplete | Compute, API, and labor costs not tracked or projected | Budget surprises; inability to calculate unit economics or ROI |
| No incident response plan | No defined process for model misbehavior in production | Ad hoc responses to output quality incidents; no post-mortems |
| Feedback loops not implemented | No mechanism for users to flag errors or for corrections to improve the system | Same errors recur; no learning from production experience |
| Scaling assumptions untested | POC cost and latency extrapolated linearly to production volume | Non-linear cost scaling; latency degradation at volume |
Organizational and Talent Failures
The talent dimension is where we often see notable gaps, and where the right enablement plan and partnerships can accelerate progress.
| Failure Mode | Description | Observable Indicator |
|---|---|---|
| Talent gap misdiagnosed | Hiring for "AI engineers" when the gap is in evaluation, domain expertise, and systems integration | Technical hires who can build models but cannot evaluate them in business context |
| Change management absent | End users not involved in design, not trained, not given feedback channels | Low adoption, workarounds, shadow AI usage |
| Misaligned incentives | Teams rewarded for launching pilots, not for production outcomes | High pilot count, low production count, no decommissioning of failed pilots |
| Vendor evaluation based on demos, not diligence | Vendor selected based on impressive demo rather than reference architecture, SLAs, and production evidence | Vendor cannot provide production case studies with measurable outcomes |
| Organizational learning not captured | Failed projects produce no documentation, no post-mortem, no institutional knowledge | Same failure patterns repeated across business units |
Modality-Specific Risk Profiles
Text-Based GenAI (LLMs)
Maturity: Most mature modality. Broadest evidence base. Primary risks: Hallucination, prompt injection, data leakage, evaluation gaps. Governance emphasis: Use-case-specific hallucination tolerance, human-in-the-loop design, continuous evaluation.
Audio and Voice AI
Evidence: Enterprise voice AI deployment track records remain limited; plan for accent and dialect variability, real-time latency constraints, higher trust thresholds for spoken interactions, and robust fallback to human agents.
Image and Video Generation
Maturity: Rapidly evolving. Enterprise use cases are narrower than consumer applications. Primary risks: Brand safety, IP provenance, factual accuracy of generated visual content, "uncanny valley" quality issues, regulatory uncertainty. Governance emphasis: Human review gates for all externally published content, IP and licensing documentation for training data, brand guideline compliance checks.
What Reliable Deployment Looks Like: A Stage-Gate Framework
The following framework represents our refined approach after helping organizations move GenAI from pilot to sustained production value. While we customize it for each client's specific context, these core principles remain consistent.
Stage 1: Problem Qualification
Gate question: Should this problem be addressed with GenAI at all?
- Business problem is clearly defined independent of technology
- Alternative approaches (rules-based, classical ML, process redesign) have been considered
- GenAI is selected because of specific capability advantages, not because of organizational pressure to "do AI"
- Executive sponsor identified with operational accountability
- Initial risk classification completed (data sensitivity, regulatory exposure, error cost)
Stage 2: Proof of Concept
Gate question: Does the technology work on representative data for this specific use case?
- Success criteria pre-registered (metrics, thresholds, evaluation methodology)
- Representative (not cherry-picked) data used for testing
- Hallucination and error rate measured and documented
- Domain expert evaluation included (not just automated metrics)
- Cost per query or transaction estimated
- Legal and compliance preliminary review completed
- Go or No-Go decision documented with rationale
Stage 3: Pilot
Gate question: Does the system perform acceptably with real users in a controlled production-like environment?
- Real users (not just developers) involved in testing
- Production-representative data volume and diversity
- Integration with existing systems tested
- Monitoring and observability infrastructure in place
- Feedback mechanism for users operational
- Fallback and graceful degradation tested
- Adversarial testing completed (edge cases, prompt injection, unexpected inputs)
- Updated cost model based on pilot data
- Go or No-Go decision documented with rationale
Stage 4: Production Deployment
Gate question: Is the system operationally ready for sustained, at-scale use?
- Operational runbook documented (monitoring, alerting, incident response, escalation)
- SLAs defined (latency, availability, accuracy)
- Drift detection and re-evaluation schedule established
- Cost monitoring and unit economics tracking active
- User training and change management completed
- Compliance and legal sign-off documented
- Data governance controls verified (access, retention, provenance)
- Vendor or model switching plan documented (if applicable)
- Decommissioning criteria defined (when to shut it down)
Stage 5: Optimization and Scaling
Gate question: Is the system delivering measurable business value, and can it be improved or expanded?
- Business outcome metrics tracked (not just technical metrics)
- ROI calculation completed with actual (not projected) data
- Continuous evaluation results reviewed on defined cadence
- User satisfaction and adoption metrics tracked
- Lessons learned documented and shared
- Scaling plan includes non-linear cost and performance modeling
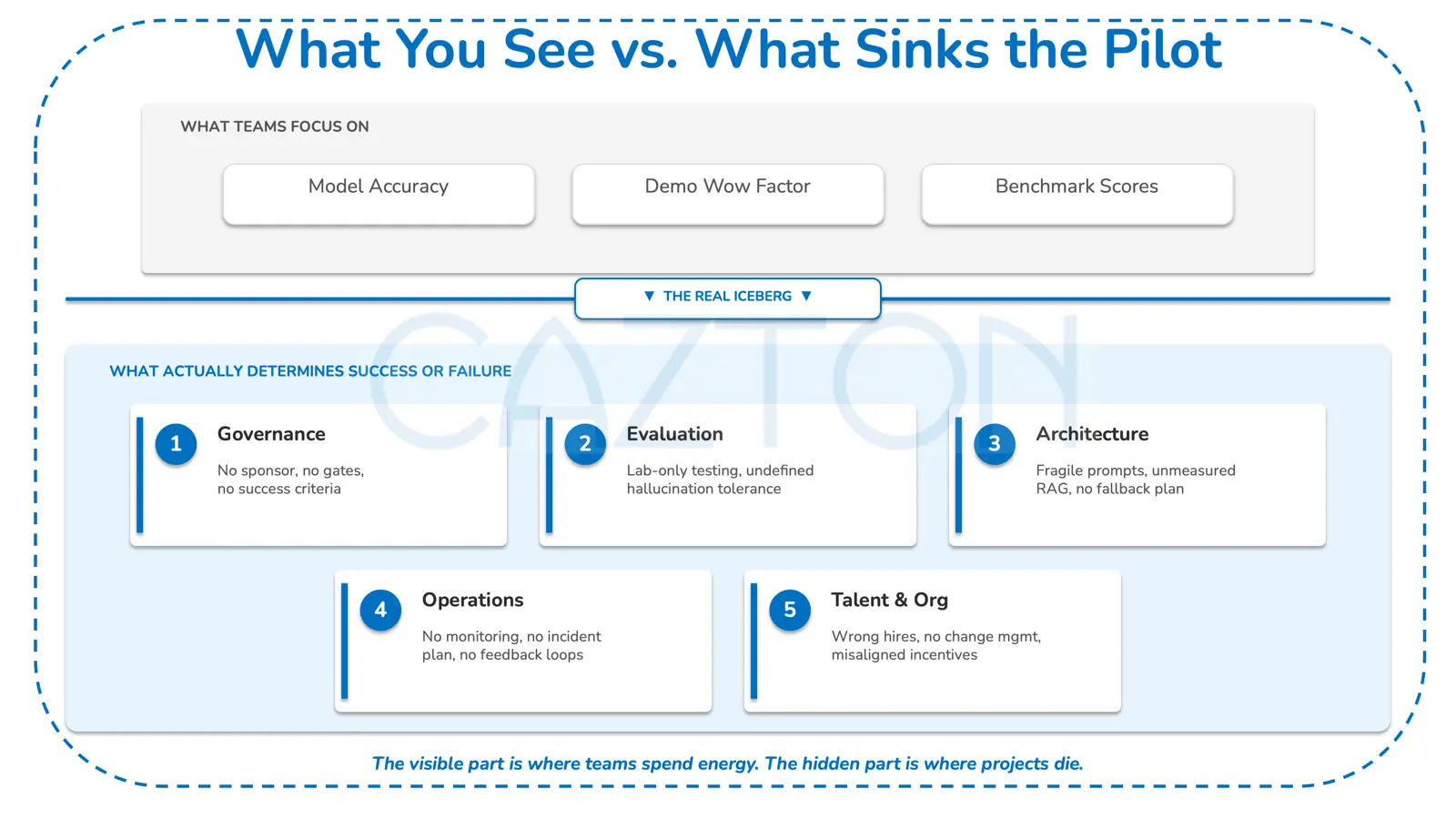
Operational Readiness Checklist
For any GenAI system moving to production, we recommend the following minimum operational infrastructure be in place:
Monitoring & Observability
- Output quality metrics defined and tracked
- Latency monitoring active
- Error rate tracking active
- Cost per query or transaction tracked
- User feedback collection mechanism operational
- Drift detection methodology defined and scheduled
Incident Response
- Incident classification scheme defined (severity levels)
- Response procedures documented for each severity level
- Escalation paths defined (technical → business → legal/compliance)
- Post-incident review process defined
- Communication templates prepared (internal and external)
Governance & Compliance
- Data processing agreements current
- Privacy impact assessment completed
- Regulatory requirements mapped and addressed
- Audit trail for model decisions maintained
- Model versioning and change management process active
Continuity & Fallback
- Fallback procedure tested and documented
- Vendor or model switching plan documented
- Data portability verified
- Decommissioning procedure documented
Decision Framework: Build, Buy, Partner, or Wait
One of the most consequential early decisions we help clients make is determining the right approach for their specific context and constraints.
| Factor | Build | Buy (SaaS/API) | Partner (Co-develop) | Wait |
|---|---|---|---|---|
| Best when | Core differentiator; unique data advantage; strong internal capability | Commodity capability; speed to market; low customization need | Domain-specific need; capability gap; shared risk appetite | Problem not well-defined; technology immature for use case; regulatory uncertainty |
| Key risk | Talent retention; maintenance burden; slower time to value | Vendor lock-in; data exposure; limited customization | Misaligned incentives; IP ownership disputes; integration complexity | Competitive disadvantage if problem is real and urgent |
| Governance emphasis | Internal capability maturity; long-term cost modeling | Vendor diligence; exit planning; SLA enforcement | Contract structure; IP clarity; shared governance model | Monitoring landscape; defining trigger conditions for re-evaluation |
Unifying Thesis
In our experience helping organizations deploy production GenAI systems, a recurring lesson is that failures are often not primarily technology problems. They are governance, evaluation, and operational maturity challenges that manifest through technology.
The models work, within documented limitations. Failures often occur in the space between model capability and organizational readiness: in undefined success criteria, in absent evaluation frameworks, in missing operational infrastructure, in talent gaps that are misdiagnosed as purely technical, and in governance structures that were designed for a different class of technology.
Organizations that approach GenAI deployment as a capability-building exercise, applying the same rigor they would to any mission-critical system, tend to achieve better outcomes than those treating it as a simple technology procurement.
The path forward is not more caution or more speed. It is more discipline.
Ready to lead the change? Let’s build something extraordinary, together. Contact Us Today!
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.