HNSW vs DiskANN
- Optimized Vector Search: Explore four powerful Approximate Nearest Neighbor Search (ANNS) methods - DiskANN, QuantizedFlat, IVF, and HNSW - each designed for different scalability and performance needs.
- DiskANN for Large-Scale Data: Leverages SSD-based storage and in-memory quantized vectors to handle massive datasets with frequent updates efficiently.
- DiskANN was developed at Microsoft Research and is generally available for vector search in Azure Cosmos DB.
- Memory-Efficient Search: QuantizedFlat and IVF reduce memory usage through vector compression and clustering, balancing accuracy and resource efficiency.
- High-Speed Retrieval: HNSW offers ultra-fast, in-memory graph-based search with high recall, ideal for scenarios where rapid query response is critical.
Introduction
Searching large datasets effectively is a challenge, especially when each data item is represented as a vector. Traditional exact search methods can be too slow or require excessive memory, making them impractical for large-scale applications. Fortunately, innovative algorithms for approximate nearest neighbor search (ANNS) have emerged, drastically reducing time and resource demands.
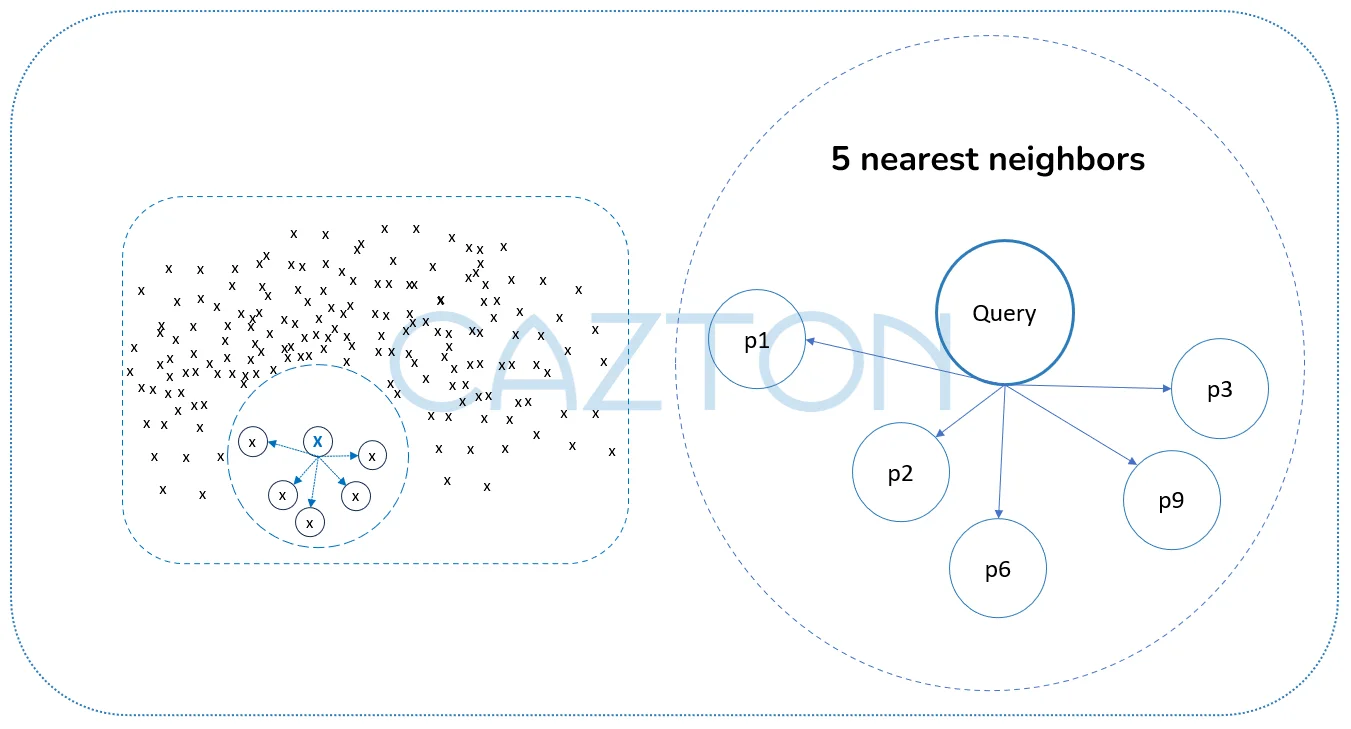
Approximate Nearest Neighbor (ANN): 5 nearest neighbors
This article explores four key ANNS methods: DiskANN, QuantizedFlat, IVF, and HNSW. Each tackles the scalability challenge from a different perspective, offering unique advantages depending on dataset size, memory availability, data mutation rates, and speed requirements.
DiskANN: Large-Scale Vector Search with SSD Optimization
Purpose
DiskANN is optimized for large datasets and maintains stable accuracy/recall even with frequent data mutations (insertions, deletions, modifications). Unlike HNSW and IVF, which often require full index rebuilds to maintain recall, DiskANN efficiently adapts to changes.
Key Features
- Graph-Based Index: Built using optimized algorithms to enable efficient search.
- Quantized Vectors in RAM: Compressed vectors stored in memory for fast retrieval.
- SSD-Based Storage: Full vectors and graph index are stored on high-speed SSDs.
- Optimized Access Patterns: Efficient interaction between in-memory quantized vectors and SSD-based graph index ensures fast query performance.
Benefits & Use Cases
- Reduces RAM usage while maintaining high recall and speed.
- Significantly cuts costs compared to in-memory indexes.
- Ideal for cost-effective, large-scale (50k – 1B+) vector search.
- Excels in high-mutation datasets (e.g., vectorized transactional data).
QuantizedFlat: Efficient Exact Search with Product Quantization
Purpose
QuantizedFlat minimizes memory usage by compressing vectors using Product Quantization (PQ) while still enabling exact nearest-neighbor (kNN) search.
Key Features
- Vector Compression: Instead of storing full-precision vectors, PQ compresses them, reducing index size and improving search speed.
- Integrated with Azure Cosmos DB: Stores quantized vectors on the bw-tree index, the same index used for term-based search.
- Two-Stage Search:
- An exact search is performed on the quantized vectors to find the top-N most similar vectors.
- The results are re-ranked based on unquantized (full-precision) vectors for higher accuracy.
Benefits & Use Cases
- Drastically reduces memory footprint.
- Speeds up exact search (kNN) with minimal loss in accuracy.
- Best suited for datasets with fewer than 50k-100k vectors.
IVF: Clustering-Based Approximate Search
Purpose
IVF improves over exact/kNN search by grouping vectors into clusters, searching for the most similar clusters, and then conducting an exact search within those clusters.
Key Features
- Two-Stage Search:
- Clusters are created using a clustering algorithm.
- The closest cluster centroids to the query vector are identified.
- A second round of search inspects the M nearest clusters, performing an exact kNN search within those clusters.
- Lower RAM Usage than HNSW: Does not require a graph structure, making it more memory-efficient.
- Static Data Limitation: To maintain accuracy with frequent data updates, clustering must be recomputed.
Benefits & Use Cases
- Lower memory usage than HNSW.
- Highly accurate when data is mostly static.
- Good for smaller datasets (500k vectors or fewer).
- Requires reclustering when data is updated or grows significantly.
- Less favored now due to graph-based methods like DiskANN and HNSW.
HNSW: Fast, In-Memory Graph-Based Index
Purpose
HNSW is an in-memory graph-based index optimized for fast query times and high recall.
Key Features
- Multi-Layer Graph Structure: Organizes data hierarchically for quick traversal.
- High Recall and Speed: Offers fast, highly accurate search at the cost of increased memory consumption.
- Can Be Combined with Quantization: HNSW-PQ (HNSW with Product Quantization) can be used to reduce memory usage.
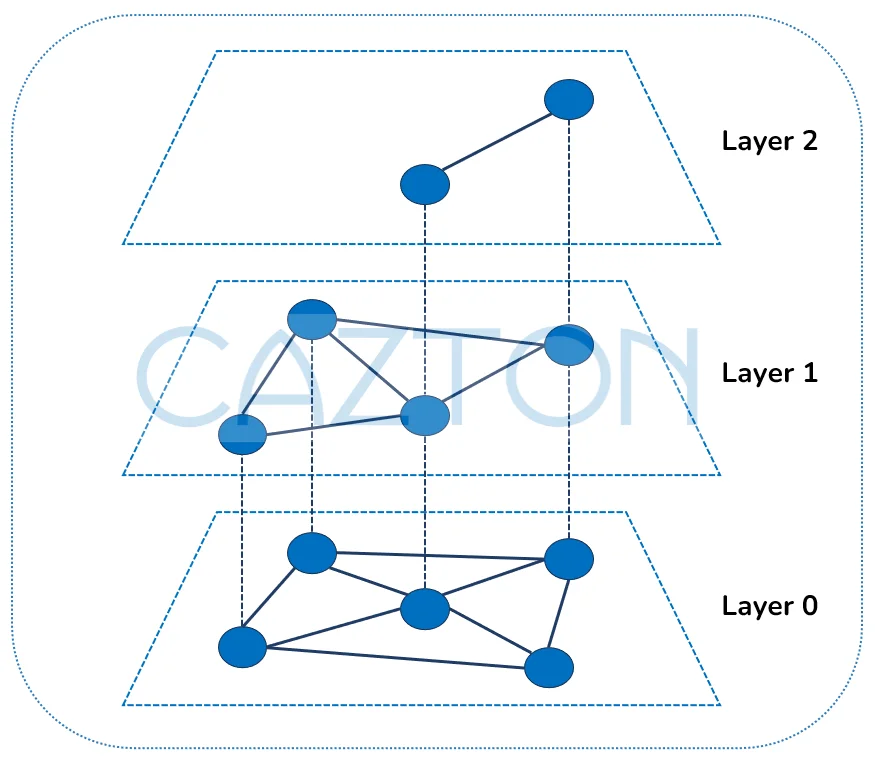
Hierarchical Navigable Small World (HNSW)
Benefits & Use Cases
- Fastest in-memory search with high recall.
- Good balance between speed and accuracy.
- Ideal when DiskANN is not available.
- High memory consumption.
- Requires full index rebuilds when data changes frequently.
When to Use Each Method?
| Method | Best For |
| DiskANN | Large datasets (100k-1B+ vectors), frequent data mutations. |
| QuantizedFlat | Small datasets (50k-100k vectors), memory-efficient exact search. |
| IVF | Proof-of-concept applications, small static datasets (up to 500k vectors) |
| HNSW | High-speed in-memory search when DiskANN is not an option |
Conclusion
Each of these methods - DiskANN, QuantizedFlat, IVF, and HNSW - serves a unique role in approximate nearest neighbor search:
- DiskANN: Best for large-scale datasets, frequent data mutations, and cost-efficient retrieval with SSD optimization.
- QuantizedFlat: Ideal for smaller datasets needing memory-efficient exact search.
- IVF: Suitable for static datasets and proof-of-concept applications.
- HNSW: A powerful in-memory approach for ultra-fast retrieval when memory constraints are not an issue.
By understanding their strengths and trade-offs, organizations can optimize their vector search strategy based on dataset size, hardware limitations, and performance needs. Whether prioritizing speed, memory efficiency, or scalability, these innovations push the boundaries of efficient nearest-neighbor retrieval.
With advancements in vector search, these methods provide a flexible and powerful foundation for AI applications, recommendation systems, and real-time search solutions.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.