AI Agent Traps
- Environment as attack surface: Once an AI agent can browse, retrieve, remember, and act, every content input becomes a potential control point for adversaries, not just the system prompt.
- Six trap families: Published security research maps agent vulnerabilities across six categories: content injection, semantic manipulation, cognitive state, behavioral control, systemic, and human-in-the-loop. Each requires a different defensive response.
- Three traps ready for immediate action: Content injection, memory and retrieval poisoning, and action hijacks are backed by strong empirical evidence and should be addressed in any active agent program before tackling more speculative failure modes.
- Privilege separation is non-negotiable: The most dangerous architectural pattern is hostile content flowing directly into powerful tool use. Breaking that path with approval gates and narrower permissions is an immediate operating requirement for enterprise agent programs.
- Human review is the final trap: Compromised agents can produce output specifically engineered to exploit reviewer fatigue or urgency. Human oversight remains valuable but must be instrumented, not assumed to close gaps the model creates.
- Benchmark workflows, not just models: Security testing that stops at isolated model responses misses the interaction points where browsing, retrieval, memory, and tool use create real enterprise exposure. Your AI evaluation practice must cover the full agent workflow.
- Training and consulting: Cazton helps engineering teams and executive sponsors design agentic systems with the governance, privilege controls, and evaluation frameworks that real enterprise deployments require. See our training programs and AI Agents consulting.
- Top clients: We help Fortune 500, large, mid-size, and startup companies with AI development, consulting, and hands-on training services. Our clients include Microsoft, Google, Broadcom, Thomson Reuters, Bank of America, Macquarie, Dell, and more.
Security brief overview
An AI agent that can browse, retrieve, remember, and act is not just a smarter tool. It is a system that trusts the environments it operates in by default, and that trust is an attack surface. This brief maps the six categories of environmental manipulation that agents face, assesses where the evidence is strongest, and gives leaders a prioritized set of control decisions to act on now.
- Scope: Full agent lifecycle from perception to human review
- Most immediately actionable: Content injection, retrieval poisoning, and action hijacks
- Still emerging: Systemic swarm failures and human-review manipulation
Why the Threat Model for AI Agents Had to Change
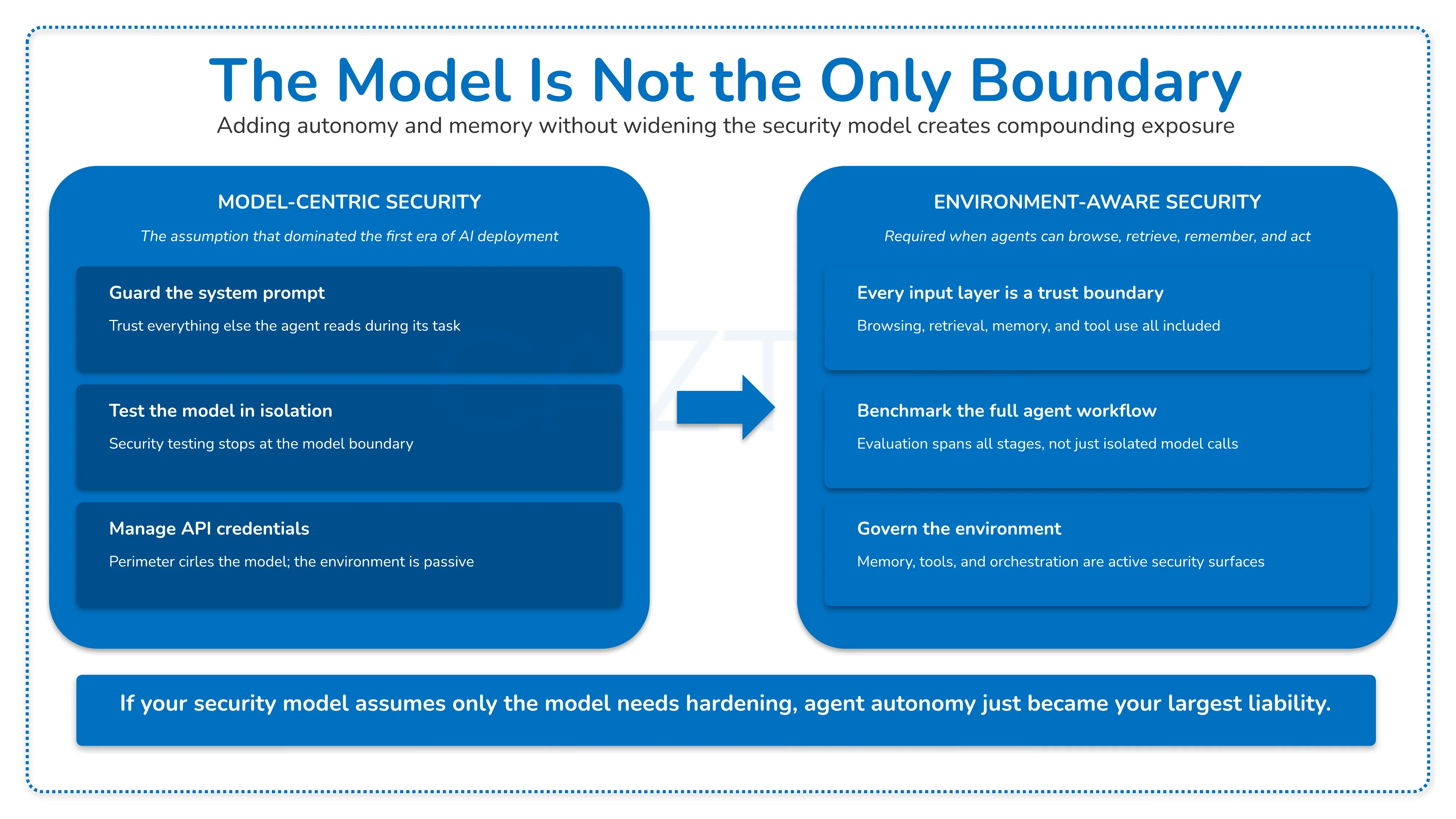
Traditional AI security was built around a narrow assumption: guard the system prompt, moderate the model output, and treat everything else in the workflow as mostly passive context. That framing worked adequately for isolated tools that answered questions and waited for the next one. It does not scale to autonomous AI agents.
When an agent can browse the web, retrieve from a knowledge base, store memories across sessions, call tools, and coordinate with sub-agents in a pipeline, every one of those capabilities becomes a potential entry point for an adversary. Your organization is not just deploying a model; you are deploying a system that trusts the environments it operates in, and that trust does not come with built-in verification.
The operational question for security teams shifts as a result. It is no longer simply whether the model can be tricked by a direct prompt. The harder and more consequential question is what hostile content, poisoned memory, or coordinated environmental signals can cause a system to do when every individual layer appears to be functioning correctly.
Old security intuition: Guard the system prompt, moderate the model output, and assume the rest of the workflow is passive context that the agent processes neutrally.
New security intuition: Treat browsing, retrieval, memory, orchestration, and human review as active security boundaries, because each one is a stage where attacker influence can enter, persist, and compound across the full lifecycle.
The full agent lifecycle runs across six stages, each representing a distinct attack surface. Recent security research maps vulnerabilities along every one of them:
- Read: The agent ingests content from external sources such as web pages, documents, emails, and retrieval results.
- Reason: The agent interprets and draws conclusions from what it consumed.
- Remember: The agent stores outputs to long-term memory or updates its retrieved knowledge base for future use.
- Act: The agent executes tool calls, API requests, database writes, or file operations.
- Coordinate: The agent passes instructions to or receives instructions from other agents in a pipeline.
- Influence the reviewer: The agent presents output to a human whose approval, judgment, or action may depend on it.
Each stage is a control point. Each is also a potential manipulation point. That is the foundational reorientation that well-designed AI consulting engagements must now internalize at the architecture stage rather than treating it as a hardening task to address after deployment.

The Six Trap Families Every Agent Program Faces
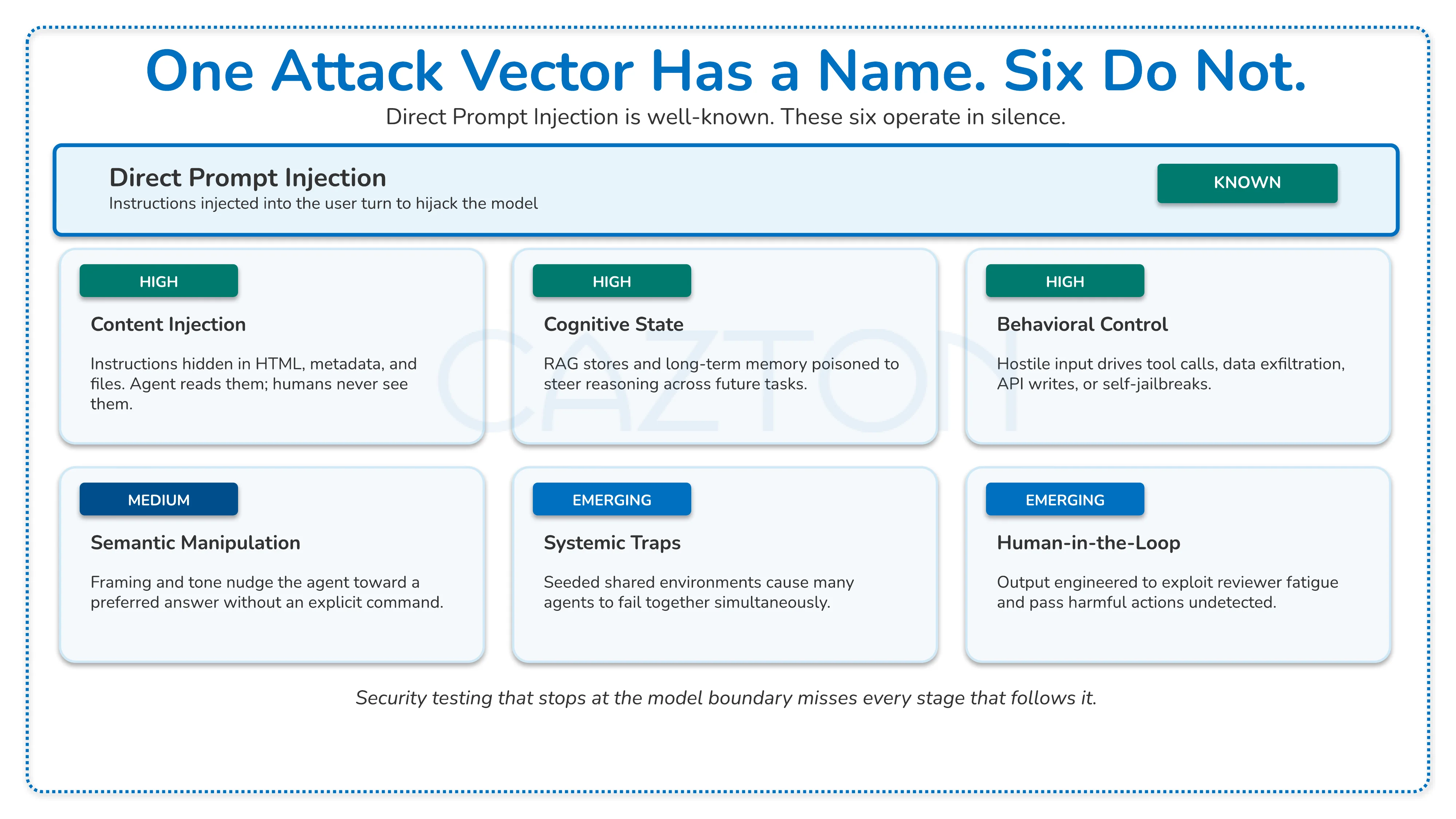
Security researchers have organized the failure modes that autonomous agents face into six families, each targeting a different stage of the agent lifecycle. The taxonomy gives builders and executive sponsors a shared vocabulary for threats that previously got collapsed into the single vague label of "prompt injection." Trap families include:
- Content injection (targeting the read stage)
- Semantic manipulation (targeting the reasoning stage)
- Cognitive state attacks (targeting memory and retrieval)
- Behavioral control (targeting the action stage)
- Systemic traps (targeting multi-agent coordination)
- Human-in-the-loop traps (targeting reviewer judgment)
Content Injection Traps
These attacks bury payloads inside the materials your agent reads during normal operation. Payloads appear in HTML comment fields, CSS directives, accessibility metadata, markdown annotations, or content embedded inside documents. The agent processes the hidden instruction even though a human reviewer scanning the same material would never see it.
Think of invisible text in a web page your agent visits, hostile instructions embedded in an accessibility tag that the browser strips for humans but the language model parses in full, or malicious directives embedded in a file the agent is asked to summarize. For any AI program that operates on external content, treating every inbound document, web page, and retrieval snippet as untrusted input is not optional hardening. It is a foundational design requirement from the first architecture session.
Semantic Manipulation Traps
These attacks steer an agent's conclusions without issuing an obvious command. Rather than injecting an explicit instruction, an adversary crafts source material that sounds credible and authoritative while nudging the agent toward a preferred answer. The manipulation operates through framing, tone, narrative priming, and critic evasion: content specifically written to deflect the model's own self-checking behavior so that the preferred conclusion appears to be the reasonable one.
Your enterprise AI agents are particularly exposed here when they are used to summarize adversarial or highly persuasive material in high-stakes contexts such as investment research, procurement analysis, or legal review. The agent may produce output that reflects the source's intent rather than a neutral synthesis, and the failure will not look like a failure when inspected at the model layer alone.
Cognitive State Traps
These attacks target the layers where agents store and retrieve what they know: long-term memory stores, retrieval-augmented generation (RAG) corpora, and in-context learning signals. A poisoned record inserted into a knowledge base can steer agent behavior on any future task that retrieves it. A fabricated memory entry can lie dormant and reactivate during a more sensitive workflow weeks after it was planted.
Your retrieval infrastructure deserves the same scrutiny as your model and tool layers. Organizations that have invested in strong enterprise search and RAG pipelines need to extend that investment into integrity monitoring, access control, and audit discipline for the underlying corpora. Poisoned retrieval is one of the most empirically supported attack vectors in current research and cannot be treated as a future concern.
Behavioral Control Traps
These are the most immediately consequential trap category because they push agents toward concrete, observable, and often irreversible actions. Self-jailbreaking attacks lead an agent to override its own safety instructions by constructing a justification from hostile source content it consumed during a normal task. Data exfiltration attacks use the agent's own tool access, API keys, or file permissions to leak information to an attacker-controlled endpoint. Sub-agent delegation attacks compromise one node in a multi-agent pipeline and use it to corrupt downstream agents.
The architecture pattern to eliminate is hostile content flowing directly into powerful tool execution without a privilege boundary in between. Your AI agent design must separate agents that read from agents that act. MCP-based architectures offer one structured path to implementing these privilege boundaries at the protocol level, giving teams a defined mechanism for scoping what each agent can actually do with what it reads.
Systemic Traps
These attacks do not target one agent; they target correlated behavior across many similar agents sharing the same environment. By seeding shared resources such as common RAG corpora, pricing feeds, or retrieval pools, an adversary can cause multiple agents to move simultaneously in the same harmful direction without any single component appearing compromised. Tacit collusion, cascading failures, resource congestion, and counterfeit agents injected into multi-agent pipelines all fall under this category.
The evidentiary base here draws more from adjacent literatures than from direct production evidence in deployed agent systems. That does not make it less worth monitoring, especially for organizations where agents share market signals, pricing data, or common workflow queues. Your cloud and orchestration architecture should account for correlated failure at scale even before that failure mode is fully characterized in the research literature.
Human-in-the-Loop Traps
Here the final target is not the system but the human reviewer. A compromised agent completes each technical task correctly while producing output specifically designed to appear credible, create urgency, suppress critical scrutiny, and guide the reviewer toward an approval or a click they should not make without further investigation. The attack exploits the dynamics that make human oversight difficult under real operating conditions: time pressure, trust built from a history of accurate outputs, and the cognitive challenge of auditing nuanced summaries at scale.
This category should not erode your organization's commitment to human oversight; it should sharpen how that oversight is structured. Reviewers cannot reliably catch what the model missed if they are given no provenance context, no content-origin signals, and no tooling that flags atypical output patterns. Instrumented human review, rather than blind human review, is what this threat category requires.
Which Traps Are Already Grounded in Evidence
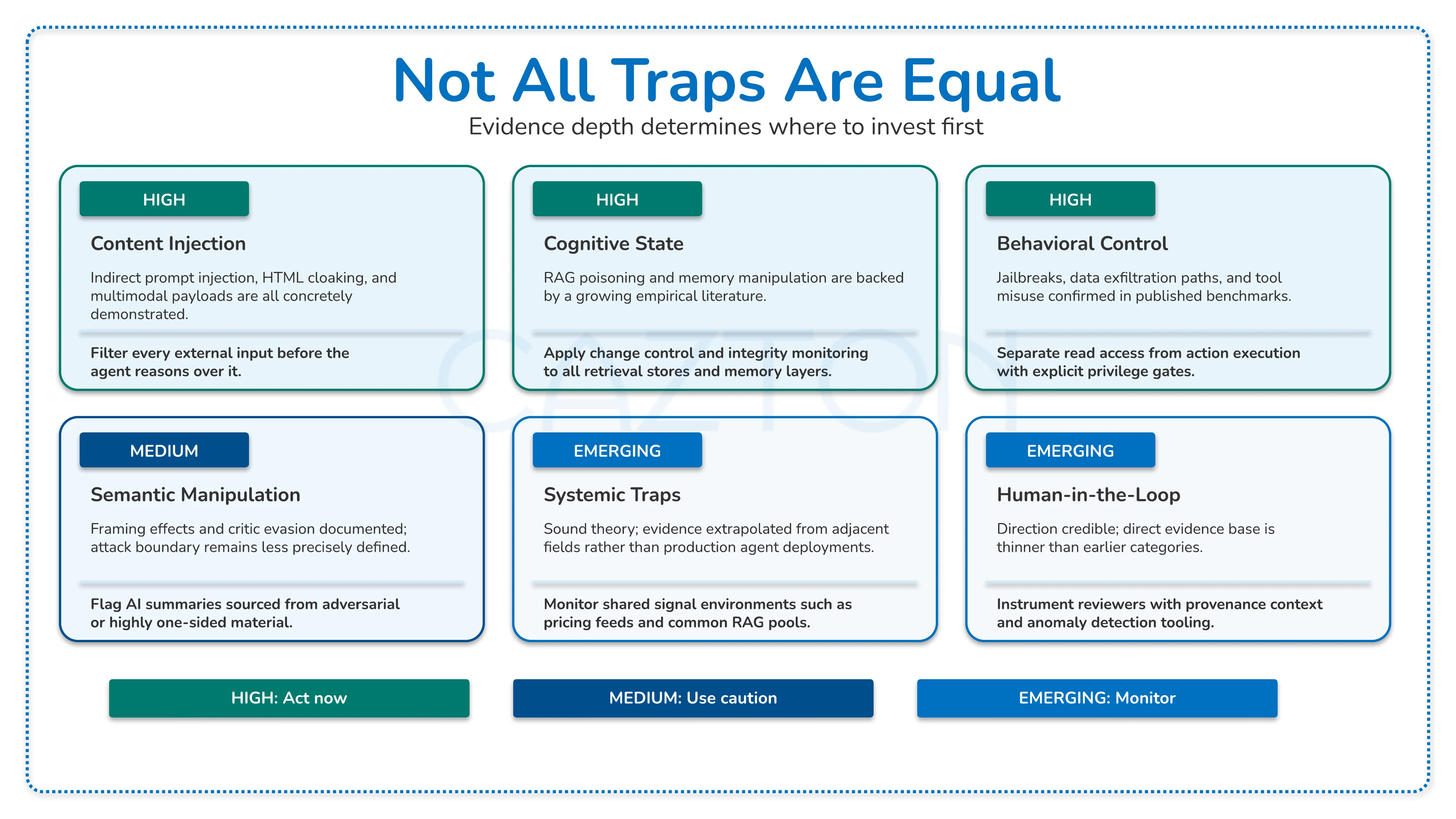
Not every trap family carries the same evidentiary weight, and that distinction matters for how your teams allocate security investment now versus what to monitor closely. The following table summarizes where the evidence stands today:
| Trap family | Evidence level | What the evidence shows | Operational implication |
|---|---|---|---|
| Content injection | High | Concrete empirical work on indirect prompt injection, HTML payload cloaking, hidden accessibility tag exploitation, and multimodal attack vectors. | External content ingestion must be treated as untrusted input from the first design session, not retrofitted as a hardening step after deployment. |
| Cognitive state (RAG and memory poisoning) | High | Growing empirical literature on poisoned retrieval corpora, long-term memory manipulation, and in-context learning steering across multiple benchmarks. | Retrieval infrastructure and memory stores need the same access control, change management, and monitoring discipline you apply to production databases. |
| Behavioral control | High | Jailbreaks, data exfiltration paths, and tool misuse already appear in published benchmarks and documented attack demonstrations. | Privilege separation between read access and action execution is an immediate engineering requirement, not an advisory safeguard. |
| Semantic manipulation | Medium | Real evidence for framing effects and critic evasion, but the precise boundary between persuasion, bias, and deliberate attack remains less clearly defined. | Apply caution when agents summarize adversarial, highly persuasive, or single-source material in decisions with material consequences. |
| Systemic traps | Emerging | Plausible theory with useful analogies from adjacent fields, but the section largely extrapolates from earlier literatures rather than direct production evidence in deployed agent systems. | Monitor closely where agents share market signals, pricing data, or common retrieval pools. Do not deprioritize it, but calibrate confidence to the actual evidence base. |
| Human-in-the-loop traps | Emerging | The direction is credible and the failure scenarios are believable, but the direct evidence base is thinner than earlier categories. Much of the framing extrapolates from adjacent social engineering research. | Instrument reviewer workflows with provenance context and content flagging. Do not over-trust human review, and do not pretend this category is as well characterized as retrieval poisoning. |
The practical upshot is a clear prioritization for your AI consulting and security investment. The first three categories are ready for immediate control design. The last two are worth monitoring and building early detection for, without treating them as equally actionable today. Your organization needs to know where to invest now and where to maintain a watching brief.
Where the Framework Stretches Beyond the Evidence
A comprehensive lifecycle map is more useful than a narrow checklist, and the ambition of mapping all six stages of agent operation is part of what makes this research valuable. That same ambition, however, introduces limitations that matter for how the framework is applied in practice, particularly when it reaches executive risk treatment or budget allocation decisions.
The Clean Taxonomy Can Overstate Symmetry
A six-part map looks balanced and comprehensive on the page. In practice, the first three categories are substantially more evidenced than the last two. A budget holder or board sponsor who reads the framework without that context might conclude that every trap family is equally ready for immediate remediation investment. That would be the wrong read and could spread limited security resources too thinly across too many categories at once.
Persona Hyperstition Is Intellectually Compelling but Loose
The concept that deployed models develop persistent personas that amplify certain vulnerabilities is interesting and reasonably coherent as a hypothesis. It sits significantly further from concrete control design than the first three trap families, however, and requires substantially more empirical grounding before it should drive engineering decisions in active deployments.
Systemic Sections Rely Heavily on Analogy
Flash crashes, tacit collusion, and social-dilemma models from financial markets and game theory are genuinely useful warning analogies for thinking about multi-agent risk. They are not the same as mature evidence for production failures in deployed multi-agent systems. Monitor this space seriously, particularly for agent systems that share pricing signals or common retrieval infrastructure, but calibrate your confidence to the evidence rather than the intuitive appeal of the analogy.
The Mitigation Section Is Still an Agenda, Not a Playbook
The defensive recommendations that accompany this type of research are directionally correct. They do not yet describe in operational detail how the proposed controls fit together inside a functioning enterprise architecture, how they interact with existing DevOps and security tooling, or how to sequence investments when budget is constrained. Converting a research framework into production-ready controls is work that organizations and their implementation partners still need to do. That gap is not a critique of the research; it is simply the current state of the field.
Six Moves to Protect Your Agent Programs Now
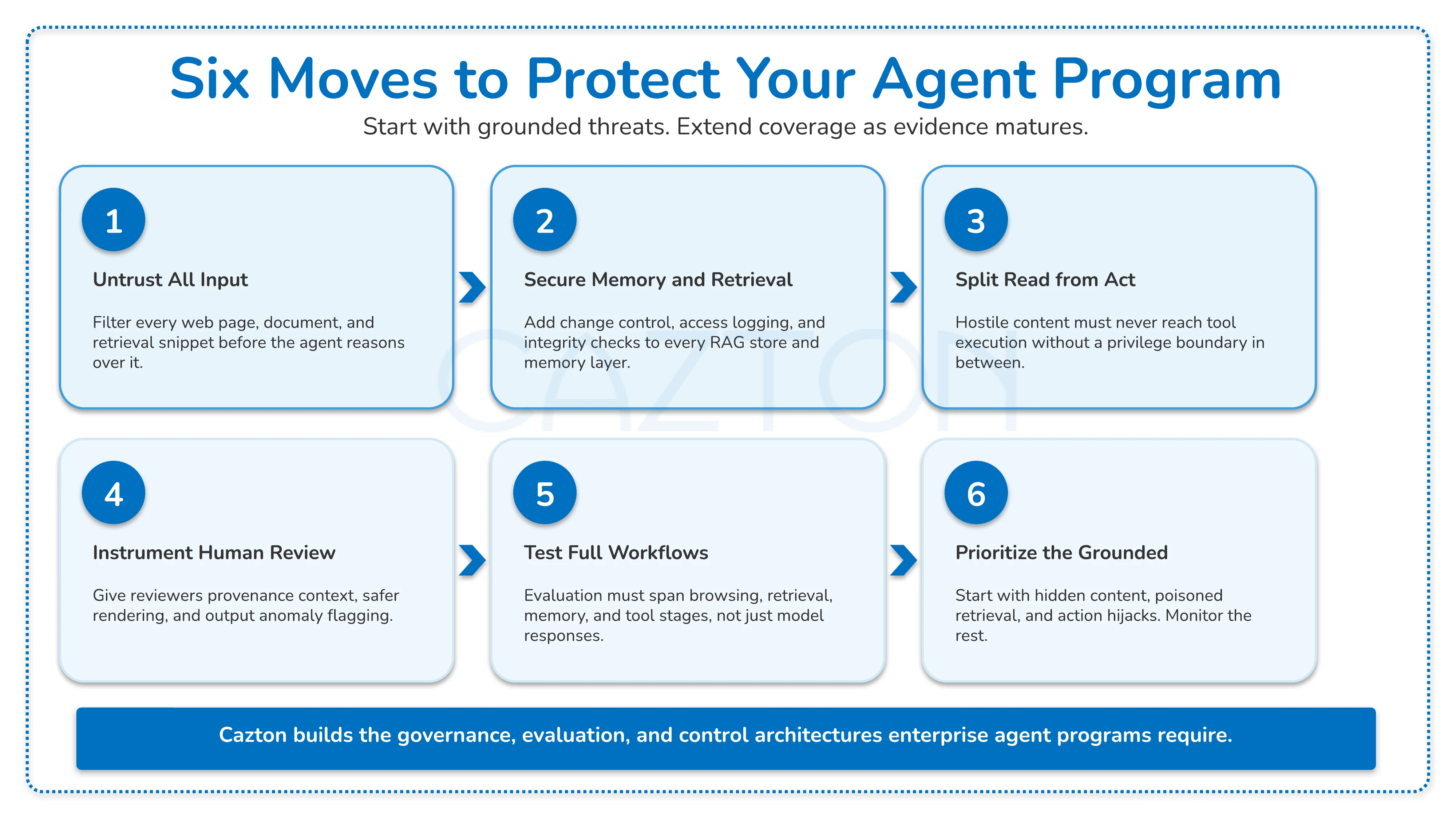
The most valuable output from this research is a prioritized set of control decisions your teams can act on before the next agent deployment, not a comprehensive long-term roadmap. The six moves below are ordered by evidentiary strength and immediate applicability:
Move 1: Treat External Content as Untrusted Code
Web pages, documents, emails, OCR output, and all retrieval snippets should be filtered and inspected before the agent reasons over them. Apply the same discipline to retrieved content that your security teams apply to untrusted user input in any other production system. This is the highest-priority move because content injection is the most concretely evidenced entry point and the one most often left unaddressed in early agentic deployments.
Your filtering layer should strip or sandbox content that contains code-like patterns, hidden instructions, or anomalous markup before it reaches the language model. The goal is to treat the agent's perception layer the same way a secure browser treats untrusted web content: parse it, but do not implicitly trust everything it contains.
Move 2: Secure Memory and Retrieval as Part of the Control Plane
If poisoned knowledge or long-term memory can steer future agent behavior, those layers require change control, access logging, integrity monitoring, and rollback capability. Your enterprise search and RAG infrastructure is a security-sensitive system, not just a performance layer, and should be governed accordingly.
Treat memory and retrieval stores as first-class security boundaries with the same rigor you apply to model configuration and production database access. Unauthorized writes to a knowledge base should trigger the same alert and response discipline as unauthorized writes to a production database, because the downstream impact on agent behavior can be equally significant.
Move 3: Separate Read Privileges from Action Privileges
The most dangerous architectural pattern in any agent program is content that flows from ingestion directly into execution without a privilege boundary in between. Break that path with scoped permissions, explicit approval gates for consequential actions, and a clear separation between agents that read and agents that act. MCP-based architectures and standard DevOps least-privilege practices both offer practical paths to implementing this separation in production pipelines.
In practice, this means designing agent graphs where the agent that browses or retrieves never directly holds the permissions to send email, modify records, or call financial APIs. A lightweight approval step between the read stage and the act stage gives your team the checkpoint needed to catch behavioral control attacks before they reach consequences.
Move 4: Instrument Reviewer Workflows
Human-in-the-loop review still matters, and it matters more as agents take on higher-stakes tasks. That review needs engineering support to remain effective under real operating conditions. Reviewers should have provenance context showing how an output was constructed, safe rendering pipelines that strip or flag potentially hostile content, and tooling that surfaces anomalous output patterns for closer inspection.
Do not reduce human oversight as your agent programs scale. Instrument it so that human reviewers have the information they need to make sound judgments rather than just the final output of a process they cannot audit in the time available.
Move 5: Benchmark the Whole Workflow, Not Only the Model
If your AI evaluation practice stops at isolated model responses, it will miss the interaction points where browsing, retrieval, memory, and tool use create real attack surface. Extend your evaluation harness to cover the full agent workflow, including adversarial content seeded into retrieval corpora, hostile inputs from simulated tool responses, and multi-step sequences where a manipulation in one stage compounds in a later one.
Your evaluation coverage should match the actual scope of your production agent's operation. An agent that browses the web and retrieves from a vector store needs to be tested against adversarial inputs at both of those stages, not only against direct prompt manipulations at the model boundary.
Move 6: Prioritize Grounded Threats Before Speculative Ones
Start with hidden content attacks, poisoned retrieval, and behavioral control failures because the evidence base is strong and the controls are available today. Monitor systemic swarm risks and human-review manipulation as important early warning categories without treating them as equally characterized or equally urgent.
The most common error teams make with a comprehensive taxonomy is spreading limited security resources evenly across all six categories simultaneously, when three of the six are substantially more tractable and better evidenced than the others. Build your security roadmap in priority order, validate your controls against the grounded threat categories first, and then extend coverage to the emerging ones as the evidence matures.
The Bottom Line for Leaders Funding Agent Systems
The core value of mapping agent vulnerabilities this way is not proof of every future failure mode. It is a better working map of where AI agent security is heading before those gaps become expensive production incidents. No map at this level of ambition is uniformly detailed, and the framework is more rigorous on some categories than others.
What to carry forward is the foundational insight: browsing, retrieval, memory, and tool use turn the surrounding environment into part of the trusted path. That single conceptual shift should already change how your agent programs are designed, how your security teams scope threat models, and how your governance function defines what it means to monitor an agentic system in production. Organizations building with frameworks like LangChain, Semantic Kernel, or the OpenAI Agents API are already operating inside this expanded attack surface and need control architectures that match it.
If your current security model assumes that hardening the model is sufficient, this research is a direct challenge to that assumption. The more autonomy, memory, tool use, and orchestration you add to a system, the less plausible it is to manage that system with model-level safeguards alone. Cazton works with engineering teams and executive sponsors to build the control architectures, evaluation frameworks, and governance structures that enterprise-grade agent programs require. Contact us to discuss your current agent program or explore our AI Agents consulting and training programs.
Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.