ElasticSearch-Part1-Index Configuration
The request for google like functionality from a single text box is common. In this series of blog posts I will describe how to implement this using ElasticSearch, and providing a code example.
The first step in this process it to determine which content will be searched over. For this sake of this blog post let's consider this website www.chanderyoga.com". In the case of ChanderYoga the desired search content are the asanas, mudras, pranayamas, and blog posts. All properties of these objects should be searchable except for the "Id" property. Below are the basic properties of these resources.
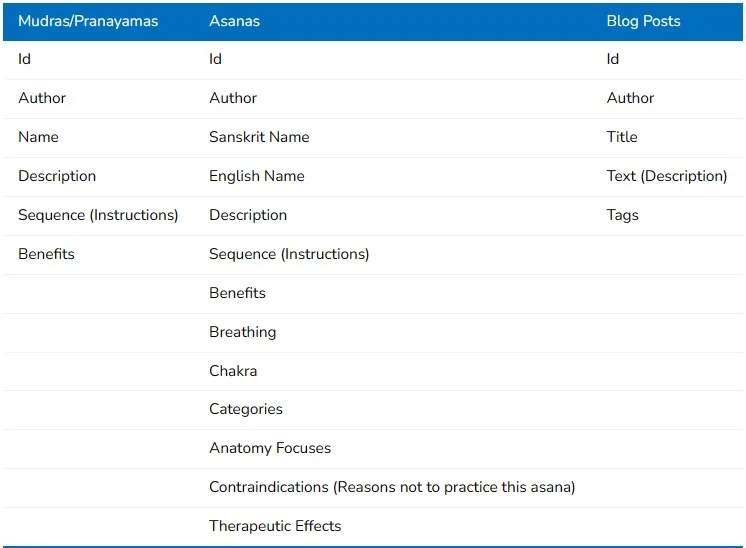
In an effort to improve the user experience we need to allow the search to match on more than just full words, we also need starts with, and contains search functionality. Since one text box determines the value being searched for we need to construct queries that allow multiple types of matches to take place, instead of creating a different query for each type of match. To do this we will use ElasticSearch's analysis and mapping to configure our indices.
First, we need to allow full word matching without case sensitivity. Different properties will need different types of analysis to get the desired effect. A name or a title should use the whitespace tokenizer, while a field containing sentences should use the standard tokenizer. The standard tokenizer uses an algorithm meant to handle European language grammar, and while that is great for large bodies of English text, it might strip out valuable characters from a name or title. Here are two custom analyzers that should fulfill these needs.
"whitespace_lowercase": { "tokenizer": "whitespace", "filter": [ "lowercase" ] }, "standard_lowercase": { "tokenizer":"standard" } The names "whitespace_lowercase" and "standard_lowercase" are names I have assigned to the combination of the existing tokenizers and filters. The lowercase filter is not necessary for the "standard_lowercase" analyzer because the standard tokenizer does this automatically.
At some point in the future we may want to sort based on the original value of fields like Name, Author, or Title; so we should use the keyword tokenizer with a lowercase filter (just in case we want to search against this at some point in the future).
"keyword_lowercase": { "tokenizer": "keyword", "filter": [ "lowercase" ] } The edge ngram tokenizer and filter built specifically for starts with searching. In this example we will create an edge ngram tokenizer and then use that in an analyzer.
Tokenizer:
"edgeNGram_tokenizer": { "type": "edgeNGram", "min_gram": "1", "max_gram":"25","token_chars": [ "letter", "digit", "punctuation", "symbol" ] } Analyzer:
"starts_with": { "tokenizer": "edgeNGram_tokenizer", "filter": [ "lowercase" ] } Our "edgeNGram_tokenizer" allows all characters except for whitespace characters, and ranges from 1 to 25 characters. The phrase "The quick brown fox", would be turned into the following tokens if analyzed by the "starts_with" analyzer: "t", "th", "the", "q", "qu", "qui", "quic", "quick", "b", "br", "bro", "brow", "brown", "f", "fo", "fox".
Finally, we need to configure an analyzer to allow contains searching. For this I have elected to use an analysis pattern that creates shingles. Shingles are groups of characters, not necessarily starting at the beginning of a word. First I will create the custom filter I want to use:
"shingle_filter": { "type": "shingle", "min_shingle_size": "2", "max_shingle_size": "5", "output_unigrams": false } The tokens fed into this filter will be grouped together, with a minimum of 2 a maximum of 5. This filter supplies a wide range of potential values to match on. I will be combining the "shingle_filter" with an ngram tokenizer:
Tokenizer:
"bigram_tokenizer": { "type": "ngram", "min_gram": "2", "max_gram": "2", "token_chars": [ "letter", "digit", "punctuation", "symbol" ] } Analyzer:
"contains_shingle": { "tokenizer": "bigram_tokenizer", "filter": [ "lowercase", "shingle_filter" ] } The tokenizer creates tokens of two characters breaking at whitespace characters. The analyzer produces the following tokens from "Chander Dhall": "ch ha", "ch ha an", "ch ha an nd", "ch ha an nd de", "ha an", "ha an nd", "ha an nd de", "ha an nd de er", "an nd", "an nd de", "an nd de er", "an nd de er dh", "nd de", "nd de er", "nd de er dh", "nd de er dh ha", "de er", "de er dh", "de er dh ha", "de er dh ha al", "er dh", "er dh ha", "er dh ha al", "er dh ha al ll", "dh ha", "dh ha al", "dh ha al ll", "ha al", "ha al ll", "al ll". While this looks very strange the same analysis will be applied to the search text as well, this gives us contains matching on a minimum of three characters and can allow some typos.
Now that we have the necessary analysis available we can map the analyzers to the fields. A field like the title of a blog post will have a mapping entry like this:
"title": { "type": "string", "analyzer": "whitespace_lowercase", "fields": { "raw": { "type": "string", "analyzer": "keyword_lowercase", "norms": { "enabled": false } }, "starts_with": { "type": "string", "index_analyzer": "starts_with", "search_analyzer": "whitespace_lowercase" }, "contains_shingle": { "type": "string", "analyzer": "contains_shingle" } } } This will actually create four fields in ElasticSearch, "title", "title.raw", "title.starts_with", "title.contains_shingle". The raw field is primarily for sorting purposes, and search requests can be written against any/all of these fields. You may notice that in the top level of "title" we use the "analyzer" field, while in the "starts_with" field we use the "index_analyzer" and "search_analyzer" fields. Using the two distinct fields, "index_analyzer" and "search_analyzer", allows me to set how the text is analyzed when it is indexed versus the analysis performed on a search. If only "analyzer" is used then the analyzer specified is used for both index and search time. While if one of "index_analyzer" or "search_analyzer" is specified the other uses the indices default analyzer (defaults to standard).
Some fields we never want to search against, like Id.
"id": { "type": "string", "index": "not_analyzed", "norms": { "enabled": false } } In the Asana resource there are many fields that have the same relevance to the search results, and I have no requirement to search against them individually. ElasticSearch gives us the ability to group these together through copy_to.
"sanskrit_name": { "type": "string", "index": "not_analyzed", "copy_to": "name", "norms": { "enabled": false } }, "english_name": { "type": "string", "index": "not_analyzed", "copy_to": "name", "norms": { "enabled": false } }, "name": { "type": "string", "analyzer": "whitespace_lowercase", "fields": { "starts_with": { "type": "string", "index_analyzer": "starts_with", "search_analyzer": "whitespace_lowercase" }, "contains_shingle": { "type": "string", "analyzer": "contains_shingle" } } } The "sanskrit_name" and "english_name" field values are held in the original field and a copy of that value is passed to the "name" field where it is analyzed for search purposes.
Full examples of index settings documents can be found in ChanderYoga.ElasticSearch.Startup.Resources. Here is the development environment version of the blog posts index.
{ "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 0 }, "analysis": { "filter": { "shingle_filter": { "type": "shingle", "min_shingle_size": "2", "max_shingle_size": "5", "output_unigrams": false } }, "tokenizer": { "edgeNGram_tokenizer": { "type": "edgeNGram", "min_gram": "1", "max_gram": "25", "token_chars": [ "letter", "digit", "punctuation", "symbol" ] }, "bigram_tokenizer": { "type": "ngram", "min_gram": "2", "max_gram": "2", "token_chars": [ "letter", "digit", "punctuation", "symbol" ] } }, "analyzer": { "whitespace_lowercase": { "tokenizer": "whitespace", "filter": [ "lowercase" ] }, "standard_lowercase": { "tokenizer": "standard", "filter": [ "lowercase" ] }, "keyword_lowercase": { "tokenizer": "keyword", "filter": [ "lowercase" ] }, "starts_with": { "tokenizer": "edgeNGram_tokenizer", "filter": [ "lowercase" ] }, "contains_shingle": { "tokenizer": "bigram_tokenizer", "filter": [ "lowercase", "shingle_filter" ] } } } }, "mappings": { "post": { "dynamic": "strict", "Id": { "path": "id" }, "_all": { "enabled": "false" }, "properties": { "id": { "type": "string", "index": "not_analyzed", "norms": { "enabled": false } }, "title": { "type": "string", "analyzer": "whitespace_lowercase", "fields": { "raw": { "type": "string", "analyzer": "keyword_lowercase", "norms": { "enabled": false } }, "starts_with": { "type": "string", "index_analyzer": "starts_with", "search_analyzer": "whitespace_lowercase" }, "contains_shingle": { "type": "string", "analyzer": "contains_shingle" } } }, "tags": { "type": "string", "analyzer": "whitespace_lowercase", "fields": { "starts_with": { "type": "string", "index_analyzer": "starts_with", "search_analyzer": "whitespace_lowercase" }, "contains_shingle": { "type": "string", "analyzer": "contains_shingle" } } }, "text": { "type": "string", "analyzer": "standard_lowercase", "fields": { "starts_with": { "type": "string", "index_analyzer": "starts_with", "search_analyzer": "standard_lowercase" }, "contains_shingle": { "type": "string", "analyzer": "contains_shingle" } } }, "author": { "type": "string", "analyzer": "whitespace_lowercase", "fields": { "raw": { "type": "string", "analyzer": "keyword_lowercase", "norms": { "enabled": false } }, "starts_with": { "type": "string", "index_analyzer": "starts_with", "search_analyzer": "whitespace_lowercase" }, "contains_shingle": { "type": "string", "analyzer": "contains_shingle" } } } } } } } Cazton is composed of technical professionals with expertise gained all over the world and in all fields of the tech industry and we put this expertise to work for you. We serve all industries, including banking, finance, legal services, life sciences & healthcare, technology, media, and the public sector. Check out some of our services:
- Artificial Intelligence
- Big Data
- Web Development
- Mobile Development
- Desktop Development
- API Development
- Database Development
- Cloud
- DevOps
- Enterprise Search
- Blockchain
- Enterprise Architecture
Cazton has expanded into a global company, servicing clients not only across the United States, but in Oslo, Norway; Stockholm, Sweden; London, England; Berlin, Germany; Frankfurt, Germany; Paris, France; Amsterdam, Netherlands; Brussels, Belgium; Rome, Italy; Sydney, Melbourne, Australia; Quebec City, Toronto Vancouver, Montreal, Ottawa, Calgary, Edmonton, Victoria, and Winnipeg as well. In the United States, we provide our consulting and training services across various cities like Austin, Dallas, Houston, New York, New Jersey, Irvine, Los Angeles, Denver, Boulder, Charlotte, Atlanta, Orlando, Miami, San Antonio, San Diego, San Francisco, San Jose, Stamford and others. Contact us today to learn more about what our experts can do for you.